plotly: biblioteca para gráficos interactivos#
![]()
NOTA IMPORTANTE
Debido a un problema de Jupyter Book (la biblioteca que se utiliza para construir el sitio web de este curso), los gráficos en plotly no se están desplegando, pero pueden verse en:
Introducción#
plotly Python es una biblioteca para la creación de gráficos interactivos que forma parte del grupo de bibliotecas de graficación de plotly, el cual también incluye bibliotecas para otros lenguajes como R, Julia, F# y MATLAB. plotly fue originalmente escrita en JavaScript, por lo que es particularmente adecuada para gráficos interactivos en la Web. Cuenta con dos módulos principales para crear gráficos: plotly.express y plotly.graph_objects.
plotly.express es una interfaz de alto nivel que facilita la creación rápida de gráficos complejos con pocas líneas de código. Se recomienda como punto de partida para programar los tipos de gráficos estadísticos más comunes.
Por su parte, plotly.graph_objects es una interfaz de bajo nivel que ofrece un control más detallado sobre cada aspecto de la visualización. Se utiliza para personalizar gráficos a profundidad o crear visualizaciones más complejas que las que se programan con plotly.express.
Carga#
# Carga de plotly.express con el alias px
import plotly.express as px
# Carga de plotly.graph_objects con el alias go
import plotly.graph_objects as go
Tipos de gráficos#
En los siguientes ejemplos, se utiliza el conjunto de datos de países de Natural Earth, el cual se carga y se configura en el siguiente bloque de código.
import pandas as pd
# Configuración de pandas para mostrar separadores de miles y 2 dígitos decimales
pd.set_option('display.float_format', '{:,.2f}'.format)
# Carga de datos de países en un dataframe
paises = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/natural-earth/paises.csv"
)
# Se usa la columna ADM0_ISO como índice
paises.set_index('ADM0_ISO', inplace=True)
# Despliegue de una muestra aleatoria de 5 filas
paises.sample(5)
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| MOZ | Mozambique | Africa | Africa | Eastern Africa | Sub-Saharan Africa | 7. Least developed region | 5. Low income | 30,366,036.00 | 15291 |
| AND | Andorra | Europe | Europe | Southern Europe | Europe & Central Asia | 2. Developed region: nonG7 | 2. High income: nonOECD | 77,142.00 | 3154 |
| GUY | Guyana | South America | Americas | South America | Latin America & Caribbean | 6. Developing region | 4. Lower middle income | 782,766.00 | 5173 |
| SGP | Singapore | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 6. Developing region | 2. High income: nonOECD | 5,703,569.00 | 372062 |
| SEN | Senegal | Africa | Africa | Western Africa | Sub-Saharan Africa | 7. Least developed region | 4. Lower middle income | 16,296,364.00 | 23578 |
Gráficos de dispersión#
Un gráfico de dispersión (en inglés, scatter plot) despliega los valores de dos variables numéricas, como puntos en un sistema de coordenadas. El valor de una variable se despliega en el eje X y el de la otra variable en el eje Y. Variables adicionales pueden ser mostradas mediante atributos de los puntos, tales como su tamaño, color o forma.
En plotly.express, los gráficos de dispersión se generan con el método plotly.express.scatter(). Se recomienda revisar el tutorial.
Ejemplos#
Población vs PIB#
# Subconjunto de países seleccionados
paises_seleccionados = paises.loc[['PAN', 'CRI', 'NIC', 'SLV', 'HND', 'GTM', 'BLZ']]
# Creación del gráfico de dispersión
fig = px.scatter(
paises_seleccionados,
x='POP_EST',
y='GDP_MD',
text=paises_seleccionados.index, # texto sobre cada punto
title='Relación entre población y producto interno bruto (PIB)',
labels={
'POP_EST': 'Población (habitantes)',
'GDP_MD': 'PIB (millones de dólares)'
}
)
# Atributos globales de la figura
fig.update_layout(
xaxis_tickformat=',',
yaxis_tickformat=',',
xaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray'),
yaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray')
)
# Atributos de los elementos visuales del gráfico
fig.update_traces(marker=dict(color='red'), textposition='top center')
# Despliegue del gráfico
fig.show()
Esperanza de vida vs PIB per cápita#
Se agrega la columna LIFE_EXPECTANCY (esperanza de vida al nacer) al dataframe paises.
# Carga de datos de esperanza de vida al nacer por país
esperanza_vida = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/world-bank/paises-esperanza-vida.csv"
)
# Se usa la columna 'Country Code' como índice
esperanza_vida.set_index('Country Code', inplace=True)
# Reducción de columnas de esperanza_vida
esperanza_vida = esperanza_vida[['2022']]
# Unión de los dataframes paises y esperanza_vida
paises = paises.join(esperanza_vida, how="left")
# Cambio de nombre de la nueva columna
paises.rename(columns={'2022': 'LIFE_EXPECTANCY'}, inplace=True)
Se agrega la columna GDP_PC (producto interno bruto per cápita) al dataframe paises.
def pib_per_capita(pib, poblacion):
"""
Retorna el PIB per cápita dados el PIB de un país (en millones de dólares) y su población.
"""
return (pib * 1000000) / poblacion
# Creación de la columna GDP_PC (PIB per cápita en dólares)
paises['GDP_PC'] = pib_per_capita(paises['GDP_MD'], paises['POP_EST'])
Se genera el gráfico de dispersión.
# Subconjunto de países seleccionados
paises_seleccionados = paises
# Eliminar valores nulos en las columnas 'GDP_MD' y 'POP_EST'
paises = paises.dropna(subset=['GDP_MD', 'POP_EST'])
# Creación del gráfico de dispersión
fig = px.scatter(
paises_seleccionados,
x='GDP_PC',
y='LIFE_EXPECTANCY',
color='CONTINENT', # para colorear los puntos por continente
title='Relación entre PIB per cápita y esperanza de vida',
labels={
'NAME': 'País',
'GDP_PC': 'PIB per cápita (dólares)',
'LIFE_EXPECTANCY': 'Esperanza de vida (años)',
'CONTINENT': 'Continente'
},
hover_data={
'NAME': True, # para mostrar la columna NAME
'GDP_PC': ':,.2f', # formato con dos decimales y separador de miles
'LIFE_EXPECTANCY': ':.2f', # formato con dos decimales
}
)
# Atributos globales de la figura
fig.update_layout(
xaxis_tickformat=',',
yaxis_tickformat=',',
xaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray'),
yaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray')
)
# Atributos de los elementos visuales del gráfico
fig.update_traces(
textposition='top center',
textfont=dict(size=6)
)
# Ajuste del eje x para que comience en 0
x_max = paises_seleccionados['GDP_PC'].max() * 1.05 # Añade un 5% de margen superior
fig.update_xaxes(range=[-2500, x_max])
# Despliegue del gráfico
fig.show()
Ejercicios#
Programe gráficos de dispersión que muestren la relación entre los siguientes indicadores del Banco Mundial:
Tasa de alfabetización de adultos y PIB per cápita.
Considere todos los países del mundo y diferentes regiones (continentes, economías, grupos de ingreso, etc.)
Gráficos de líneas#
Un gráfico de líneas muestra información en la forma de puntos de datos, llamados marcadores (markers), conectados por segmentos de líneas rectas. Es similar a un gráfico de dispersión pero, además del uso de segmentos de línea, tiene la particularidad de que los datos están ordenados, usualmente con respecto al eje X. Los gráficos de línea son usados frecuentemente para mostrar tendencias a través del tiempo.
En plotly.express, los gráficos de líneas se generan mediante el método plotly.express.line(). Se recomienda revisar el tutorial.
Ejemplos#
Evolución en el tiempo de la esperanza de vida al nacer#
# Carga de datos de esperanza de vida al nacer por país
esperanza_vida = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/world-bank/paises-esperanza-vida.csv"
)
# Filtrar datos de países
paises_seleccionados = esperanza_vida[
esperanza_vida['Country Code'].isin(
['CRI', 'TCD', 'COL', 'FRA', 'HTI', 'JPN', 'MEX', 'NZL', 'UKR', 'USA', 'ZAF']
)
]
# Despliegue de los datos de los países
paises_seleccionados
| Country Name | Country Code | Indicator Name | Indicator Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | ... | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | Unnamed: 68 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45 | Colombia | COL | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 57.13 | 57.73 | 58.30 | 58.89 | 59.38 | 59.81 | ... | 76.26 | 76.47 | 76.65 | 76.75 | 76.75 | 74.77 | 72.83 | 73.66 | NaN | NaN |
| 48 | Costa Rica | CRI | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 60.41 | 60.90 | 61.11 | 61.62 | 62.08 | 62.66 | ... | 79.09 | 79.46 | 79.38 | 79.48 | 79.43 | 79.28 | 77.02 | 77.32 | NaN | NaN |
| 77 | France | FRA | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 69.87 | 70.12 | 70.31 | 70.51 | 70.66 | 70.81 | ... | 82.32 | 82.57 | 82.58 | 82.68 | 82.83 | 82.18 | 82.32 | 82.23 | NaN | NaN |
| 100 | Haiti | HTI | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 43.50 | 43.91 | 44.29 | 42.77 | 44.97 | 45.35 | ... | 63.24 | 63.39 | 63.85 | 64.02 | 64.25 | 64.05 | 63.19 | 63.73 | NaN | NaN |
| 119 | Japan | JPN | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 67.70 | 68.35 | 68.63 | 69.71 | 70.21 | 70.27 | ... | 83.79 | 83.98 | 84.10 | 84.21 | 84.36 | 84.56 | 84.45 | 84.00 | NaN | NaN |
| 154 | Mexico | MEX | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 55.02 | 55.83 | 56.60 | 57.31 | 57.95 | 58.50 | ... | 74.68 | 74.41 | 74.14 | 74.02 | 74.20 | 70.13 | 70.21 | 74.83 | NaN | NaN |
| 180 | New Zealand | NZL | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 71.24 | 70.99 | 71.23 | 71.28 | 71.33 | 71.23 | ... | 81.61 | 81.66 | 81.86 | 81.71 | 82.06 | 82.26 | 82.21 | 82.76 | NaN | NaN |
| 229 | Chad | TCD | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 38.37 | 38.63 | 38.84 | 39.07 | 39.33 | 39.12 | ... | 51.59 | 52.08 | 52.31 | 52.83 | 53.26 | 52.78 | 52.52 | 53.00 | NaN | NaN |
| 248 | Ukraine | UKR | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 69.49 | 69.57 | 69.33 | 69.79 | 70.21 | 69.87 | ... | 71.19 | 71.48 | 71.78 | 71.58 | 71.83 | 71.19 | 69.65 | 68.59 | NaN | NaN |
| 251 | United States | USA | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 69.77 | 70.27 | 70.12 | 69.92 | 70.17 | 70.21 | ... | 78.69 | 78.54 | 78.54 | 78.64 | 78.79 | 76.98 | 76.33 | 77.43 | NaN | NaN |
| 263 | South Africa | ZAF | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 52.67 | 53.09 | 53.38 | 53.63 | 53.91 | 54.19 | ... | 63.95 | 64.75 | 65.40 | 65.67 | 66.17 | 65.25 | 62.34 | 61.48 | NaN | NaN |
11 rows × 69 columns
# Se seleccionan las columnas de años
anios = esperanza_vida.columns[4:68]
paises_seleccionados = paises_seleccionados[['Country Name', 'Country Code'] + list(anios)]
paises_seleccionados
| Country Name | Country Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | ... | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45 | Colombia | COL | 57.13 | 57.73 | 58.30 | 58.89 | 59.38 | 59.81 | 60.20 | 60.53 | ... | 76.04 | 76.26 | 76.47 | 76.65 | 76.75 | 76.75 | 74.77 | 72.83 | 73.66 | NaN |
| 48 | Costa Rica | CRI | 60.41 | 60.90 | 61.11 | 61.62 | 62.08 | 62.66 | 63.37 | 63.92 | ... | 78.77 | 79.09 | 79.46 | 79.38 | 79.48 | 79.43 | 79.28 | 77.02 | 77.32 | NaN |
| 77 | France | FRA | 69.87 | 70.12 | 70.31 | 70.51 | 70.66 | 70.81 | 70.96 | 71.16 | ... | 82.72 | 82.32 | 82.57 | 82.58 | 82.68 | 82.83 | 82.18 | 82.32 | 82.23 | NaN |
| 100 | Haiti | HTI | 43.50 | 43.91 | 44.29 | 42.77 | 44.97 | 45.35 | 45.59 | 46.12 | ... | 62.99 | 63.24 | 63.39 | 63.85 | 64.02 | 64.25 | 64.05 | 63.19 | 63.73 | NaN |
| 119 | Japan | JPN | 67.70 | 68.35 | 68.63 | 69.71 | 70.21 | 70.27 | 70.92 | 71.47 | ... | 83.59 | 83.79 | 83.98 | 84.10 | 84.21 | 84.36 | 84.56 | 84.45 | 84.00 | NaN |
| 154 | Mexico | MEX | 55.02 | 55.83 | 56.60 | 57.31 | 57.95 | 58.50 | 58.98 | 59.42 | ... | 74.80 | 74.68 | 74.41 | 74.14 | 74.02 | 74.20 | 70.13 | 70.21 | 74.83 | NaN |
| 180 | New Zealand | NZL | 71.24 | 70.99 | 71.23 | 71.28 | 71.33 | 71.23 | 71.12 | 71.47 | ... | 81.46 | 81.61 | 81.66 | 81.86 | 81.71 | 82.06 | 82.26 | 82.21 | 82.76 | NaN |
| 229 | Chad | TCD | 38.37 | 38.63 | 38.84 | 39.07 | 39.33 | 39.12 | 39.15 | 39.48 | ... | 51.20 | 51.59 | 52.08 | 52.31 | 52.83 | 53.26 | 52.78 | 52.52 | 53.00 | NaN |
| 248 | Ukraine | UKR | 69.49 | 69.57 | 69.33 | 69.79 | 70.21 | 69.87 | 69.73 | 69.56 | ... | 71.19 | 71.19 | 71.48 | 71.78 | 71.58 | 71.83 | 71.19 | 69.65 | 68.59 | NaN |
| 251 | United States | USA | 69.77 | 70.27 | 70.12 | 69.92 | 70.17 | 70.21 | 70.21 | 70.56 | ... | 78.84 | 78.69 | 78.54 | 78.54 | 78.64 | 78.79 | 76.98 | 76.33 | 77.43 | NaN |
| 263 | South Africa | ZAF | 52.67 | 53.09 | 53.38 | 53.63 | 53.91 | 54.19 | 54.39 | 54.63 | ... | 63.38 | 63.95 | 64.75 | 65.40 | 65.67 | 66.17 | 65.25 | 62.34 | 61.48 | NaN |
11 rows × 66 columns
# Se transforman los datos de formato ancho a formato largo
datos_largos = paises_seleccionados.melt(
id_vars=['Country Name', 'Country Code'],
value_vars=anios,
var_name='Year',
value_name='Life Expectancy'
)
datos_largos
| Country Name | Country Code | Year | Life Expectancy | |
|---|---|---|---|---|
| 0 | Colombia | COL | 1960 | 57.13 |
| 1 | Costa Rica | CRI | 1960 | 60.41 |
| 2 | France | FRA | 1960 | 69.87 |
| 3 | Haiti | HTI | 1960 | 43.50 |
| 4 | Japan | JPN | 1960 | 67.70 |
| ... | ... | ... | ... | ... |
| 699 | New Zealand | NZL | 2023 | NaN |
| 700 | Chad | TCD | 2023 | NaN |
| 701 | Ukraine | UKR | 2023 | NaN |
| 702 | United States | USA | 2023 | NaN |
| 703 | South Africa | ZAF | 2023 | NaN |
704 rows × 4 columns
# Creación del gráfico de líneas
fig = px.line(
datos_largos,
x='Year',
y='Life Expectancy',
color='Country Name',
markers=True,
title='Evolución en el tiempo de la esperanza de vida al nacer',
labels={
'Year': 'Año',
'Life Expectancy': 'Esperanza de vida al nacer (años)',
'Country Name': 'País'
},
hover_data={
'Country Name': True, # para mostrar la columna NAME
'Year': True, # formato con dos decimales y separador de miles
'Life Expectancy': ':.2f', # formato con dos decimales
}
)
# Atributos globales de la figura
fig.update_layout(
legend_title_text='País',
xaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray'),
yaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray')
)
# Despliegue del gráfico
fig.show()
Ejercicios#
Agregue más países al gráfico de evolución en el tiempo de la esperanza de vida al nacer.
Elabore un gráfico similar para el indicador de mortalidad infantil. Utilice datos de varios países.
Modifique el gráfico de la esperanza de vida para incluir todos los países de África subsahariana, sin listar uno por uno todos los países.
Gráficos de barras#
Un gráfico de barras se compone de barras rectangulares con longitud proporcional a estadísticas (ej. frecuencias, promedios, mínimos, máximos) asociadas a una variable categórica o discreta. Las barras pueden ser horizontales o verticales y se recomienda que estén ordenadas según su longitud, a menos que exista un orden inherente a la variable (ej. el orden de los días de la semana). Es uno de los tipos de gráficos estadísticos más antiguos y comunes y tiene la ventaja de ser muy fácil de comprender.
En plotly.express, los gráficos de barras se generan mediante el método plotly.express.bar(). Se recomiendar leer el tutorial.
Ejemplos#
Suma de población por continente#
Gráfico de barras verticales:
# Cálculo de la suma de población por continente
poblacion_continente_suma = paises.groupby('CONTINENT')['POP_EST'].sum().sort_values(ascending=False).reset_index()
# Creación del gráfico de barras verticales
fig = px.bar(
poblacion_continente_suma,
x='CONTINENT',
y='POP_EST',
title='Suma de población por continente',
labels={
'CONTINENT': 'Continente',
'POP_EST': 'Población (habitantes)'
},
width=1000, # Ancho de la figura en píxeles
height=600 # Alto de la figura en píxeles
)
# Actualizar el formato del eje y evitar notación científica
fig.update_yaxes(tickformat=",d")
# Atributos globales de la figura
fig.update_layout(
title=dict(
x=0.5, # Centrar el título
font=dict(size=20)
),
xaxis_title=dict(
font=dict(size=16)
),
yaxis_title=dict(
font=dict(size=16)
)
)
# Despliegue del gráfico
fig.show()
Gráfico de barras horizontales (debe utilizarse el argumento orientation=h en px.bar()):
# Cálculo de la suma de población por continente
poblacion_continente_suma = paises.groupby('CONTINENT')['POP_EST'].sum().sort_values(ascending=True).reset_index()
# Creación de gráfico de barras verticales
fig = px.bar(
poblacion_continente_suma,
x='POP_EST',
y='CONTINENT',
orientation='h',
title='Total de población por continente',
labels={
'CONTINENT': 'Continente',
'POP_EST': 'Población (habitantes)'
},
width=1000, # Ancho de la figura en píxeles
height=600 # Alto de la figura en píxeles
)
# Actualizar el formato del eje y evitar notación científica
fig.update_xaxes(tickformat=",d")
# Atributos globales de la figura
fig.update_layout(
title=dict(
x=0.5, # Centrar el título
font=dict(size=20)
),
xaxis_title=dict(font=dict(size=16)),
yaxis_title=dict(font=dict(size=16))
)
# Despliegue del gráfico
fig.show()
Suma de población por región y subregión de la ONU#
Barras apiladas#
Con el argumento color=SUBREGION puede generarse un gráfico de barras apiladas (en inglés, stacked) en el que para cada región se muestran sus subregiones.
# Suma de población por región y subregión de la ONU
# Con reset_index() se evita la creación de un índice y
# así es posible usar más fácilmente todas las columnas en el gráfico
poblacion_region_subregion_suma = paises.groupby(['REGION_UN', 'SUBREGION'])['POP_EST'].sum().reset_index()
# Ordenar las regiones por población total descendente
poblacion_total_region = poblacion_region_subregion_suma.groupby('REGION_UN')['POP_EST'].sum().sort_values(ascending=False).index
# Asignar el orden de las categorías en el eje X
poblacion_region_subregion_suma['REGION_UN'] = pd.Categorical(
poblacion_region_subregion_suma['REGION_UN'],
categories=poblacion_total_region,
ordered=True
)
# Creación del gráfico de barras apiladas
fig = px.bar(
poblacion_region_subregion_suma,
x='REGION_UN',
y='POP_EST',
color='SUBREGION',
title='Total de población por región y subregión de la ONU',
labels={
'REGION_UN': 'Región',
'SUBREGION': 'Subregión',
'POP_EST': 'Población (habitantes)'
},
category_orders={'REGION_UN': poblacion_total_region}, # Aplicar el orden de las regiones
width=1000, # Ancho de la figura en píxeles
height=600 # Alto de la figura en píxeles
)
# Actualizar el formato del eje y para evitar notación científica
fig.update_yaxes(tickformat=",d")
# Atributos globales de la figura
fig.update_layout(
title=dict(
x=0.5, # Centrar el título
font=dict(size=20)
),
xaxis_title=dict(font=dict(size=16)),
yaxis_title=dict(font=dict(size=16)),
legend_title=dict(
text='Subregión',
font=dict(size=16)
),
legend=dict(
title_font_size=16,
font_size=14,
x=1.05, # Posición horizontal de la leyenda
y=1 # Posición vertical de la leyenda
)
)
# Despliegue del gráfico
fig.show()
Barras agrupadas#
Otra forma de mostrar barras con diferentes niveles de agrupación son las barras agrupadas, con el argumento barmode=group en la función fig.update.layout().
# Suma de población por región y subregión de la ONU
poblacion_region_subregion_suma = paises.groupby(['REGION_UN', 'SUBREGION'])['POP_EST'].sum().reset_index()
# Ordenar las regiones por población total descendente
poblacion_total_region = poblacion_region_subregion_suma.groupby('REGION_UN')['POP_EST'].sum().sort_values(ascending=False).index
# Asignar el orden de las categorías en el eje X
poblacion_region_subregion_suma['REGION_UN'] = pd.Categorical(
poblacion_region_subregion_suma['REGION_UN'],
categories=poblacion_total_region,
ordered=True
)
# Creación del gráfico de barras agrupadas con Plotly Express
fig = px.bar(
poblacion_region_subregion_suma,
x='REGION_UN',
y='POP_EST',
color='SUBREGION',
title='Suma de población por región y subregión de la ONU',
labels={
'REGION_UN': 'Región',
'SUBREGION': 'Subregión',
'POP_EST': 'Población (habitantes)'
},
category_orders={'REGION_UN': poblacion_total_region}, # Aplicar el orden de las regiones
width=1000, # Ancho de la figura en píxeles
height=600 # Alto de la figura en píxeles
)
# Actualizar el formato del eje y para evitar notación científica
fig.update_yaxes(tickformat=",d")
# Personalizar el diseño para barras agrupadas
fig.update_layout(
barmode='group', # Establecer el modo de barras a 'group' para barras agrupadas
title=dict(
x=0.5, # Centrar el título
font=dict(size=20)
),
xaxis_title=dict(font=dict(size=16)),
yaxis_title=dict(font=dict(size=16)),
legend_title=dict(
text='Subregión',
font=dict(size=16)
),
legend=dict(
title_font_size=16,
font_size=14,
x=1.05, # Posición horizontal de la leyenda
y=1 # Posición vertical de la leyenda
)
)
# Despliegue del gráfico
fig.show()
Ejercicios#
Programe gráficos de barras para:
Suma de PIB (
GDP_MD) por economía (ECONOMY).Promedio de PIB per cápita por grupo de ingresos (
INCOME_GRP).
Gráficos de pastel#
Un gráfico de pastel representa porcentajes y porciones en secciones (slices) de un círculo. Son muy populares, pero también son criticados debido a la dificultad del cerebro humano de comparar áreas de sectores circulares, por lo que algunos expertos recomiendan sustituirlos por otros tipos de gráficos como, por ejemplo, gráficos de barras.
En plotly.express, los gráficos de pastel se implementan con el método plotly.express.pie(). Se recomienda leer el tutorial.
# Cálculo de la suma de población por continente
poblacion_continente_suma = paises.groupby('CONTINENT')['POP_EST'].sum().sort_values(ascending=True).reset_index()
# Creación del gráfico de pastel
fig = px.pie(
poblacion_continente_suma,
names='CONTINENT',
values='POP_EST',
title='Total de población por continente',
labels={'CONTINENT': 'Continente', 'POP_EST': 'Población (habitantes)'}
)
# Atributos globales de la figura
fig.update_layout(
legend_title_text='Continente'
)
# Atributos de las propiedades visuales
fig.update_traces(textposition='inside', textinfo='percent')
# Despliegue del gráfico
fig.show()
Ejercicios#
Pruebe los siguientes argumentos y observe el resultado:
hole=0.3(enpx.pie())textposition='outside'(enfig.update_traces())textinfo='percent+label'(enfig.update_traces())marker=dict(colors=px.colors.qualitative.Pastel)(enfig.update_traces())
Histogramas#
Un histograma es una representación gráfica de la distribución de una variable numérica en forma de barras (en este caso, llamadas en inglés bins). La longitud de cada barra representa la frecuencia de un rango de valores de la variable. La graficación de la distribución de las variables es, frecuentemente, una de las primeras tareas que se realiza cuando se explora un conjunto de datos.
En plotly.express, los histogramas se implementan con la función plotly.express.histogram(). Se recomienda leer el tutorial.
El siguiente bloque de código muestra la distibución de la variable población estimada (POP_EST) mediante un histograma.
# Para evitar países con población menor que 0
paises_seleccionados = paises[paises['POP_EST'] >= 0]
# Creación del histograma
fig = px.histogram(
paises_seleccionados,
x='POP_EST',
nbins=10, # Cantidad de bins
title='Distribución de la población estimada por país',
labels={
'POP_EST': 'Población estimada (habitantes)'
}
)
# Atributos globales de la figura
fig.update_layout(
xaxis_tickformat=',',
yaxis_tickformat=',',
xaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray'),
yaxis=dict(showgrid=True, gridwidth=0.5, gridcolor='lightgray'),
yaxis_title='Cantidad de países'
)
# Mostrar el gráfico
fig.show()
Gráficos de caja#
Un gráfico de caja (boxplot) muestra información de una variable numérica a través de su mediana, sus cuartiles (Q1, Q2 y Q3) y sus valores atípicos. Se acostumbra combinarlo con variables categóricas para agrupar los datos y facilitar la comparación entre categorías. Es especialmente útil para identificar la dispersión, la mediana, la variabilidad y posibles valores atípicos en los datos.
En plotly.express, los gráficos de caja se implementan con la función plotly.express.box(). Se recomienda leer el tutorial.
La Fig. 25 muestra los componentes de un gráfico de caja.
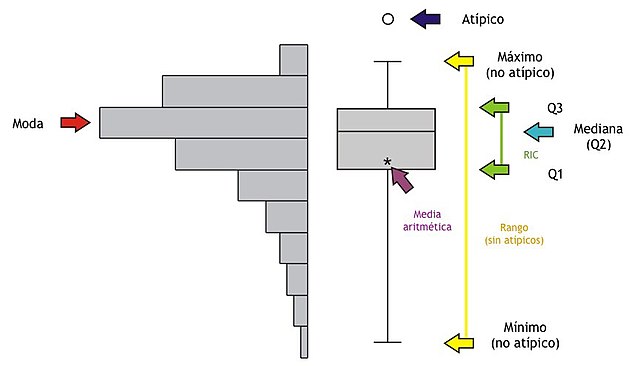
Fig. 25 Componentes de un diagrama de caja. Imagen de Onkel Dagobert..#
{kind=link}
El siguiente bloque de código genera un gráfico de caja para la esperanza de vida al nacer.
# Generación del diagrama de caja
fig = px.box(
paises,
y='LIFE_EXPECTANCY',
title='Esperanza de vida al nacer en países',
labels={'LIFE_EXPECTANCY': 'Esperanza de vida al nacer (años)'},
hover_data=['NAME']
)
# Despliegue del gráfico
fig.show()
El siguiente bloque muestra el mismo gráfico categorizado por continente.
# Generación del gráfico
fig = px.box(
paises,
x='CONTINENT',
y='LIFE_EXPECTANCY',
title='Esperanza de vida al nacer por continente',
labels={
'LIFE_EXPECTANCY': 'Esperanza de vida al nacer',
'CONTINENT': 'Continente',
'NAME': 'País'
},
hover_data={
'NAME': True,
'LIFE_EXPECTANCY': ':.2f', # formato con dos decimales
}
)
# Despliegue del gráfico
fig.show()
Ejercicios#
Pruebe el argumento
points='all'enpx.bo()y observe el resultado.Programe un gráfico de caja para la variable mortalidad infantil categorizada por regiones del Banco Mundial.
Otros#
Climogramas#
Un climograma es un gráfico estadístico que combina las variables climáticas de temperatura y precitipación a lo largo de un período de tiempo, para una región o lugar específico. Permite visualizar las condiciones climáticas de un área, facilitando el análisis de patrones estacionales y tendencias climáticas.
Un climograma puede tomar varias formas. Una de las más usuales es la de un gráfico de barras combinado con un gráfico de líneas. Las barras representan las unidades de tiempo (ej. meses) y su longitud el valor de una de las variables (ej. precipitación), mientras que la línea muestra los valores de la otra variable (ej. temperatura).
En los siguientes bloques de código se genera un climograma con datos de temperatura y precipitación de ERA5. ERA5 es el quinto conjunto de datos de reanálisis atmosférico global producido por el Centro Europeo de Predicción a Medio Plazo (ECMWF). Es una reconstrucción del clima de la Tierra, desde 1950 hasta la actualidad.
Los datos que se utilizan en el climograma corresponden a los promedios mensuales de temperatura a 2 m de la superficie y de precipitación total para todo el territorio de Costa Rica, entre los años 2004 y 2023. Se utilizó una cuadrícula de 0.1 x 0.1 grados decimales.
En este gráfico se utilizará el módulo plotly.graph_objects.
# Carga de datos de clima
clima = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/era5/temperatura-precipitacion-cri-2004-2023.csv"
)
# Despliegue de los datos
clima
| mes | temperatura | precipitacion | |
|---|---|---|---|
| 0 | Enero | 22.15 | 3.98 |
| 1 | Febrero | 22.60 | 2.92 |
| 2 | Marzo | 23.16 | 2.73 |
| 3 | Abril | 23.67 | 4.72 |
| 4 | Mayo | 23.46 | 11.91 |
| 5 | Junio | 23.12 | 12.44 |
| 6 | Julio | 22.87 | 11.75 |
| 7 | Agosto | 22.95 | 12.03 |
| 8 | Septiembre | 22.91 | 11.77 |
| 9 | Octubre | 22.59 | 14.74 |
| 10 | Noviembre | 22.24 | 12.65 |
| 11 | Diciembre | 22.13 | 6.32 |
# Creación de una figura
fig = go.Figure()
# Añadir las barras de precipitación
fig.add_trace(
go.Bar(
x=clima['mes'],
y=clima['precipitacion'],
name='Precipitación (mm)',
marker_color='blue',
yaxis='y1'
)
)
# Añadir la línea de temperatura
fig.add_trace(
go.Scatter(
x=clima['mes'],
y=clima['temperatura'],
name='Temperatura (°C)',
mode='lines+markers',
marker=dict(color='red'),
line=dict(color='red'),
yaxis='y2'
)
)
# Propiedades globales de la figura
fig.update_layout(
title='Precipitación y Temperatura Promedio Mensual en Costa Rica (2004-2023)',
xaxis=dict(
title='Mes',
tickmode='linear'
),
yaxis=dict(
title='Precipitación (mm)',
titlefont=dict(color='blue'),
tickfont=dict(color='blue')
),
yaxis2=dict(
title='Temperatura (°C)',
titlefont=dict(color='red'),
tickfont=dict(color='red'),
overlaying='y',
side='right'
),
legend=dict(
x=0.01,
y=0.99,
bgcolor='rgba(255,255,255,0)',
bordercolor="Black",
borderwidth=1
),
template='plotly_white',
width=900,
height=600
)
# Despliegue del gráfico
fig.show()