matplotlib: biblioteca para visualización de datos#
![]()
Introducción#
La biblioteca matplotlib es una de las más populares de Python para visualización de datos. Se utiliza principalmente para crear gráficos estáticos en dos dimensiones, pero también puede emplearse para generar visualizaciones animadas, interactivas y en tres dimensiones.
matplotlib se compone de varios módulos, siendo pyplot el principal y el más utilizado.
Instalación y carga#
# Carga del módulo pyplot de matplotlib con el alias plt
import matplotlib.pyplot as plt
# Módulo para configurar las marcas ("ticks") de los ejes de los gráficos
from matplotlib import ticker
Interfaces#
matplotlib cuenta con dos interfaces para crear visualizaciones: una basada en la clase Axes y otra basada en el módulo pyplot.
Interfaz de Axes (basada en objetos, explícita)#
Esta interfaz es orientada a objetos y utiliza métodos para tareas como agregar datos, configurar los límites de los ejes y especificar etiquetas, entre otras. Permite controlar una gran cantidad de detalles y se recomienda para visualizaciones complejas o con múltiples gráficos.
La estructura principal de una visualización programada con esta interfaz consta de objetos de dos clases:
Figure(figura): es el contenedor general de los gráficos. Puede verse como un canvas o lienzo en el que estos se dibujan.Axes(gráficos o subgráficos): son los gráficos contenidos en la figura. Un objeto de la claseAxescontiene elementos visuales como geometrías (líneas, barras, histogramas, etc.), títulos y etiquetas.
En el siguiente bloque de código se genera una figura con un gráfico.
# Figura con:
# - Gráfico de dispersión que muestra la relación entre estatura y peso.
# Datos
estatura = [1.77, 1.57, 1.8, 1.6, 1.63, 1.69, 1.75, 1.8, 1.9, 1.55, 1.65, 1.71, 1.85, 1.73, 1.62]
peso = [75.1, 62.9, 78.4, 61.2, 67.8, 71.1, 75.5, 81.6, 82.2, 64.4, 65.6, 72.2, 90.3, 74.3, 66.7]
# Creación una figura con espacio para un gráfico
fig, ax = plt.subplots()
# Creación de un gráfico de dispersión
ax.scatter(estatura, peso)
# Personalización del gráfico
ax.set_title('Relación entre estatura y peso')
ax.set_xlabel('Estatura (m)')
ax.set_ylabel('Peso (kg)')
# Despliegue de la figura
plt.show()
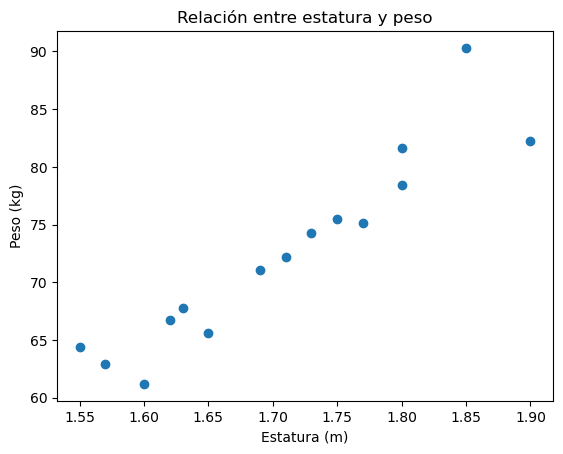
En este ejemplo se utilizaron los siguientes métodos:
El método
matplotlib.pyplot.subplots()retorna, en una tupla, una figura y un conjunto de gráficos. La figura se almacena en el objetofigy el único gráfico en el objetoax.El método
matplotlib.axes.Axes.scatter()genera un gráfico de dispersión (scatter plot) en el subgráficoax.Los métodos
matplotlib.axes.Axes.set_title(),matplotlib.axes.Axes.set_xlabel()ymatplotlib.axes.Axes.set_ylabel()ayudan a personalizar el gráficoaxal especificar respectivamente el título, la etiqueta del eje x y la etiqueta del eje y.Por último, el método
matplotlib.pyplot.show()despliega todas las figuras que han sido creadas. En este caso, solo se despliegafig. Una figura específica puede desplegarse con el métodomatplotlib.figure.Figure.show(). Sin embargo, debe tenerse en cuenta que este último método puede no funcionar adecuadamente en ambientes interactivos como cuadernos de notas de Jupyter.
La interfaz basada en subgráficos también puede utilizarse para generar figuras con varios gráficos, como en el siguiente bloque de código:
# Figura con:
# - Gráfico de dispersión que muestra la relación entre estatura y peso.
# - Gráfico de dispersión que muestra la relación entre peso y grasa corporal.
# Datos
estatura = [1.77, 1.57, 1.8, 1.6, 1.63, 1.69, 1.75, 1.8, 1.9, 1.55, 1.65, 1.71, 1.85, 1.73, 1.62]
peso = [75.1, 62.9, 78.4, 61.2, 67.8, 71.1, 75.5, 81.6, 82.2, 64.4, 65.6, 72.2, 90.3, 74.3, 66.7]
grasa_corporal = [19.43, 20.88, 19.59, 19.29, 20.96, 20.53, 20.09, 20.7, 17.96, 22.67, 19.35, 20.25, 22.26, 20.37, 20.88]
# Creación de una figura de 8x6 pulgadas
# con espacio para dos gráficos distribuidos en 2 filas y 1 columna
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(8, 6))
# Creación del primer gráfico de dispersión en ax1
ax1.scatter(estatura, peso, c='blue')
# Creación del segundo gráfico de dispersión en ax12
ax2.scatter(peso, grasa_corporal, c='red')
# Personalización de ax1
ax1.set_title('Relación entre estatura y peso')
ax1.set_xlabel('Estatura (m)')
ax1.set_ylabel('Peso (kg)')
# Personalización de ax2
ax2.set_title('Relación entre peso y grasa corporal')
ax2.set_xlabel('Peso (kg)')
ax2.set_ylabel('Grasa corporal (%)')
# Ajuste del espacio entre los gráficos
plt.tight_layout()
# Despliegue de la figura
plt.show()
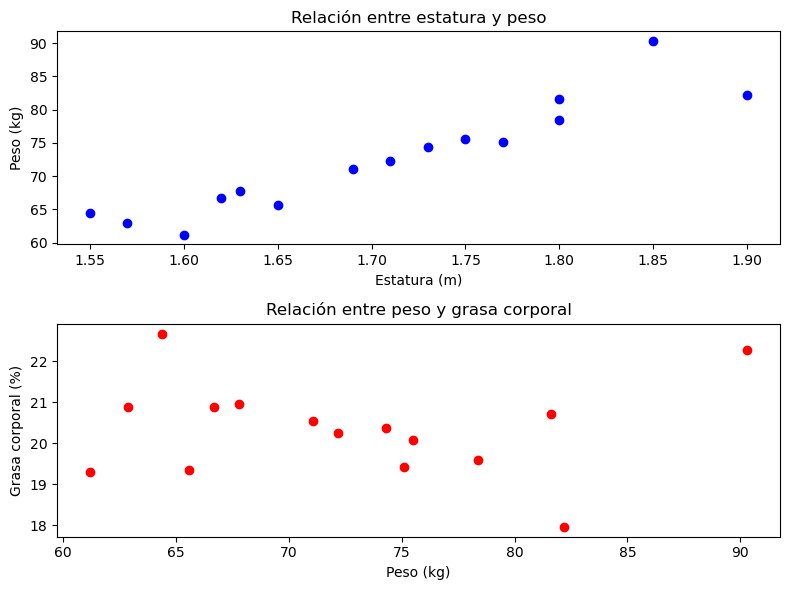
En este caso, el método matplotlib.pyplot.subplots() fue llamado con los argumentos nrows y ncols correspondientes a la cantidad de filas (1) y de columnas (2), lo que proporciona espacio para dos gráficos: ax1 y ax2. El argumento figsize especifica el tamaño de la figura en pulgadas (8 de ancho x 6 de alto). El método matplotlib.pyplot.tight_layout() ajusta el espacio entre y alrededor de los gráficos. En matplotlib.axes.Axes.scatter() se usa el argumento c para especificar el color de los puntos.
En este curso, se prefiere esta interfaz por ser más adecuada para gráficos complejos y proporcionar mayor control.
Interfaz de pyplot (basada en funciones, implícita)#
Esta interfaz es conveniente para gráficos simples y rápidos. La mayoría de las funciones se llaman directamente desde pyplot. Las clases Figure y Axes se manipulan a través de estas funciones, sin tener que declarar objetos, por lo que se dice que se usan de manera “implícita”.
El siguiente bloque de código genera un gráfico mediante esta interfaz.
# Figura con:
# - Gráfico de dispersión que muestra la relación entre estatura y peso.
# Datos
estatura = [1.77, 1.57, 1.8, 1.6, 1.63, 1.69, 1.75, 1.8, 1.9, 1.55, 1.65, 1.71, 1.85, 1.73, 1.62]
peso = [75.1, 62.9, 78.4, 61.2, 67.8, 71.1, 75.5, 81.6, 82.2, 64.4, 65.6, 72.2, 90.3, 74.3, 66.7]
# Creación de un gráfico de dispersión
plt.scatter(estatura, peso)
# Personalización del gráfico
plt.title('Relación entre estatura y peso')
plt.xlabel('Estatura (m)')
plt.ylabel('Peso (kg)')
# Despliegue de la figura
plt.show()
En esta visualización, las funciones matplotlib.pyplot.scatter(), matplotlib.pyplot.title(), matplotlib.pyplot.xlabel() y matplotlib.pyplot.ylabel() y matplotlib.pyplot.show() acceden a una figura y a un gráfico que han sido creados de manera implícita por pyplot.
Integración con pandas#
pandas cuenta con un sistema de graficación basado en matplotlib, lo que permite crear gráficos directamente a partir de series y dataframes de pandas.
El método pandas.DataFrame.plot() genera gráficos de diferentes tipos, los cuales se especifican por medio del argumento kind (kind=’bar’, kind=’pie’, kind=’hist’, kind=’scatter’, etc.). Cada tipo de gráfico puede generarse también a través de funciones como pandas.DataFrame.plot.bar(), pandas.DataFrame.plot.pie(), pandas.DataFrame.plot.hist(), pandas.DataFrame.plot.scatter() y otras.
Tipos de gráficos#
En los siguientes ejemplos, se utiliza el conjunto de datos de países de Natural Earth, el cual se carga y se configura en el siguiente bloque de código.
import pandas as pd
# Configuración de pandas para mostrar separadores de miles y 2 dígitos decimales
pd.set_option('display.float_format', '{:,.2f}'.format)
# Carga de datos de países en un dataframe
paises = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/natural-earth/paises.csv"
)
# Se usa la columna ADM0_ISO como índice
paises.set_index('ADM0_ISO', inplace=True)
# Despliegue de una muestra aleatoria de 5 filas
paises.sample(5)
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| UZB | Uzbekistan | Asia | Asia | Central Asia | Europe & Central Asia | 6. Developing region | 4. Lower middle income | 33,580,650.00 | 57921 |
| MMR | Myanmar | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 7. Least developed region | 5. Low income | 54,045,420.00 | 76085 |
| ISL | Iceland | Europe | Europe | Northern Europe | Europe & Central Asia | 2. Developed region: nonG7 | 1. High income: OECD | 361,313.00 | 24188 |
| TTO | Trinidad and Tobago | North America | Americas | Caribbean | Latin America & Caribbean | 6. Developing region | 2. High income: nonOECD | 1,394,973.00 | 24269 |
| B28 | W. Sahara | Africa | Africa | Northern Africa | Middle East & North Africa | 7. Least developed region | 5. Low income | 603,253.00 | 907 |
Gráficos de dispersión#
Un gráfico de dispersión (en inglés, scatter plot) despliega los valores de dos variables numéricas, como puntos en un sistema de coordenadas. El valor de una variable se despliega en el eje X y el de la otra variable en el eje Y. Variables adicionales pueden ser mostradas mediante atributos de los puntos, tales como su tamaño, color o forma.
En matplotlib, los gráficos de dispersión se generan con el método pandas.DataFrame.plot.scatter().
Ejemplos#
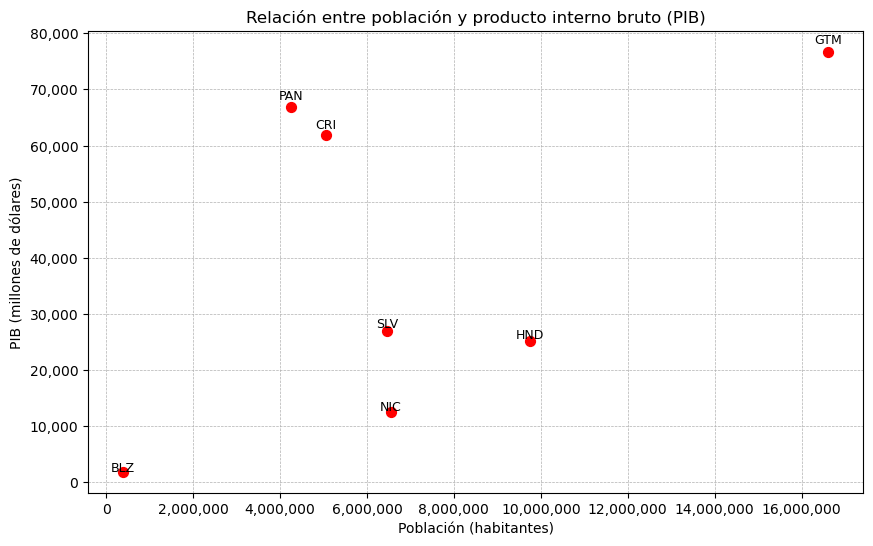
Población vs PIB#
# Subconjunto de países seleccionados
paises_seleccionados = paises.loc[['PAN', 'CRI', 'NIC', 'SLV', 'HND', 'GTM', 'BLZ']]
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de dispersión
paises_seleccionados.plot.scatter(
ax=ax,
x='POP_EST',
y='GDP_MD',
color='red',
s=50
)
# Etiquetas en cada punto
desplazamiento_x = 1
desplazamiento_y = 1.02
for i, row in paises_seleccionados.iterrows():
ax.text(
x=row['POP_EST']*desplazamiento_x,
y=row['GDP_MD']*desplazamiento_y,
s=i,
fontsize=9,
ha='center'
)
# Personalización del gráfico
ax.set_title('Relación entre población y producto interno bruto (PIB)')
ax.set_xlabel('Población (habitantes)')
ax.set_ylabel('PIB (millones de dólares)')
# Configuración de marcas en los ejes para evitar la notación científica
ax.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# Cuadrícula
ax.grid(True, which='both', linestyle='--', linewidth=0.5)
# Despliegue del gráfico
plt.show()
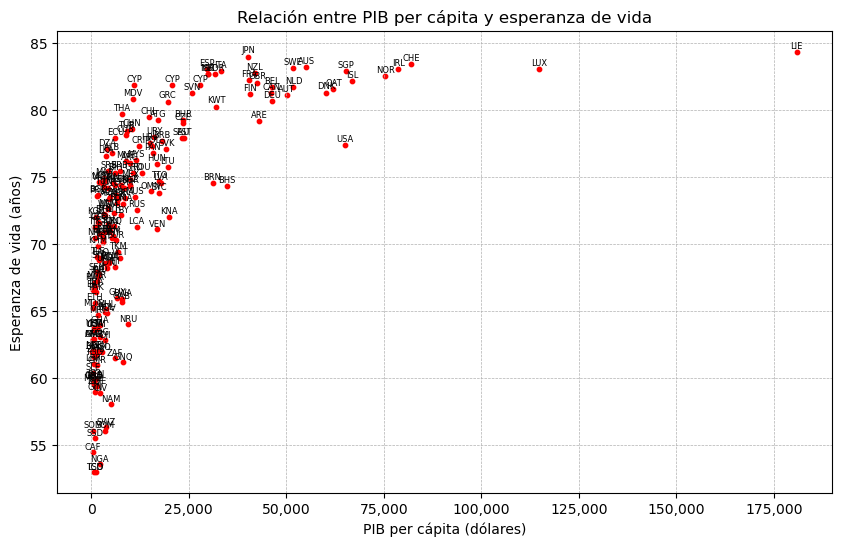
Esperanza de vida vs PIB per cápita#
Se agrega la columna LIFE_EXPECTANCY (esperanza de vida al nacer) al dataframe paises.
# Carga de datos de esperanza de vida al nacer por país
esperanza_vida = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/world-bank/paises-esperanza-vida.csv"
)
# Se usa la columna 'Country Code' como índice
esperanza_vida.set_index('Country Code', inplace=True)
# Reducción de columnas de esperanza_vida
esperanza_vida = esperanza_vida[['2022']]
# Unión de los dataframes paises y esperanza_vida
paises = paises.join(esperanza_vida, how="left")
# Cambio de nombre de la nueva columna
paises.rename(columns={'2022': 'LIFE_EXPECTANCY'}, inplace=True)
Se agrega la columna GDP_PC (producto interno bruto per cápita) al dataframe paises.
def pib_per_capita(pib, poblacion):
"""
Retorna el PIB per cápita dados el PIB de un país (en millones de dólares) y su población.
"""
return (pib * 1000000) / poblacion
# Creación de la columna GDP_PC (PIB per cápita en dólares)
paises['GDP_PC'] = pib_per_capita(paises['GDP_MD'], paises['POP_EST'])
Se genera el gráfico de dispersión.
# Subconjunto de países seleccionados
# paises_seleccionados = paises.loc[['PAN', 'CRI', 'NIC', 'SLV', 'HND', 'GTM', 'BLZ']]
# paises_seleccionados = paises[paises['REGION_UN'] == 'Americas']
# paises_seleccionados = paises[paises['REGION_UN'] == 'Africa']
paises_seleccionados = paises
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de dispersión
paises_seleccionados.plot.scatter(
ax=ax,
x='GDP_PC',
y='LIFE_EXPECTANCY',
color='red',
s=10
)
# Etiquetas en cada punto
desplazamiento_x = 1
desplazamiento_y = 1.003
for i, row in paises_seleccionados.iterrows():
ax.text(
x=row['GDP_PC']*desplazamiento_x,
y=row['LIFE_EXPECTANCY']*desplazamiento_y,
s=i,
fontsize=6,
ha='center'
)
# Personalización del gráfico
ax.set_title('Relación entre PIB per cápita y esperanza de vida')
ax.set_xlabel('PIB per cápita (dólares)')
ax.set_ylabel('Esperanza de vida (años)')
# Configuración de marcas en los ejes para evitar la notación científica
ax.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# Cuadrícula
ax.grid(True, which='both', linestyle='--', linewidth=0.5)
# Despliegue del gráfico
plt.show()
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
posx and posy should be finite values
Ejercicios#
Programe gráficos de dispersión que muestren la relación entre los siguientes indicadores del Banco Mundial:
Tasa de alfabetización de adultos y PIB per cápita.
Considere todos los países del mundo y diferentes regiones (continentes, economías, grupos de ingreso, etc.)
Gráficos de líneas#
Un gráfico de líneas muestra información en la forma de puntos de datos, llamados marcadores (markers), conectados por segmentos de líneas rectas. Es similar a un gráfico de dispersión pero, además del uso de segmentos de línea, tiene la particularidad de que los datos están ordenados, usualmente con respecto al eje X. Los gráficos de línea son usados frecuentemente para mostrar tendencias a través del tiempo.
En matplotlib, los gráficos de barras se generan mediante el método pandas.DataFrame.plot().
Ejemplos#
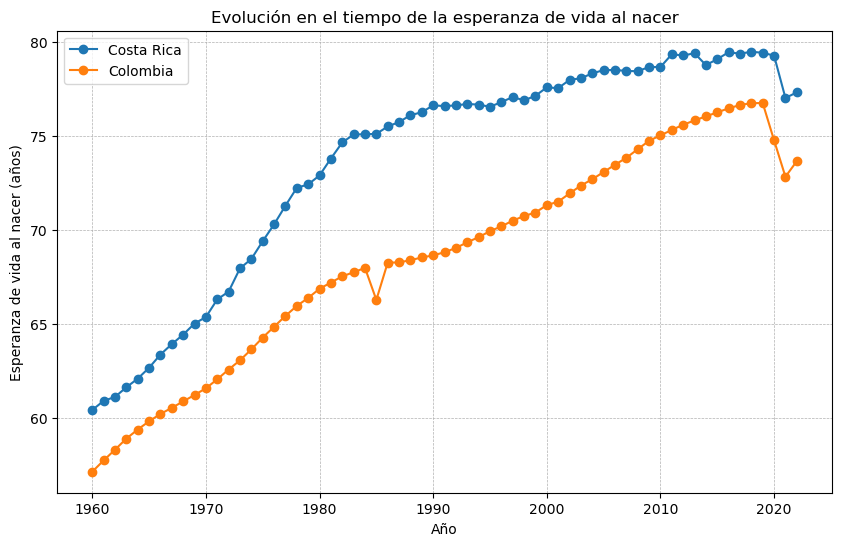
Evolución en el tiempo de la esperanza de vida al nacer#
# Carga de datos de esperanza de vida al nacer por país
esperanza_vida = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/world-bank/paises-esperanza-vida.csv"
)
# Filtro de datos para un país
datos_cri = esperanza_vida[esperanza_vida['Country Code'] == 'CRI']
# Filtro de datos para otro país
datos_col = esperanza_vida[esperanza_vida['Country Code'] == 'COL']
# Despliegue de los datos de uno de los países
datos_col
| Country Name | Country Code | Indicator Name | Indicator Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | ... | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | 2023 | Unnamed: 68 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45 | Colombia | COL | Life expectancy at birth, total (years) | SP.DYN.LE00.IN | 57.13 | 57.73 | 58.30 | 58.89 | 59.38 | 59.81 | ... | 76.26 | 76.47 | 76.65 | 76.75 | 76.75 | 74.77 | 72.83 | 73.66 | NaN | NaN |
1 rows × 69 columns
# Se conservan solo las columnas correspondientes a los años
datos_cri = datos_cri.iloc[0, 4:68]
datos_col = datos_col.iloc[0, 4:68]
datos_col
1960 57.13
1961 57.73
1962 58.30
1963 58.89
1964 59.38
...
2019 76.75
2020 74.77
2021 72.83
2022 73.66
2023 NaN
Name: 45, Length: 64, dtype: object
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de líneas del primer país
datos_cri.plot(
ax=ax,
marker='o',
label='Costa Rica'
)
# Creación del gráfico de líneas del segundo país
datos_col.plot(
ax=ax,
marker='o',
label='Colombia'
)
# Personalización del gráfico
ax.set_title('Evolución en el tiempo de la esperanza de vida al nacer')
ax.set_xlabel('Año')
ax.set_ylabel('Esperanza de vida al nacer (años)')
ax.legend() # Se muestra la leyenda para identificar las líneas
# Cuadrícula
ax.grid(True, which='both', linestyle='--', linewidth=0.5)
# Despliegue del gráfico
plt.show()
Ejercicios#
Agregue más países al gráfico de evolución en el tiempo de la esperanza de vida al nacer.
Elabore un gráfico similar para el indicador de mortalidad infantil. Utilice datos de varios países.
Gráficos de barras#
Un gráfico de barras se compone de barras rectangulares con longitud proporcional a estadísticas (ej. frecuencias, promedios, mínimos, máximos) asociadas a una variable categórica o discreta. Las barras pueden ser horizontales o verticales y se recomienda que estén ordenadas según su longitud, a menos que exista un orden inherente a la variable (ej. el orden de los días de la semana). Es uno de los tipos de gráficos estadísticos más antiguos y comunes y tiene la ventaja de ser muy fácil de comprender.
En matplotlib, los gráficos de barras se generan mediante los métodos pandas.DataFrame.plot.bar(), para barras verticales, y pandas.DataFrame.plot.barh(), para barras horizontales.
Ejemplos#
Suma de población por continente#
Gráfico de barras verticales.
# Suma de población por continente
poblacion_continente_suma = paises.groupby('CONTINENT')['POP_EST'].sum()
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de barras
# Es recomendable que las barras se muestren en orden
poblacion_continente_suma.sort_values(ascending=False).plot.bar(ax=ax)
# Personalización del gráfico
ax.set_title('Suma de población por continente')
ax.set_xlabel('Continente')
ax.set_ylabel('Población (habitantes)')
# Configuración de marcas en los ejes para evitar la notación científica
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# Despliegue del gráfico
plt.show()
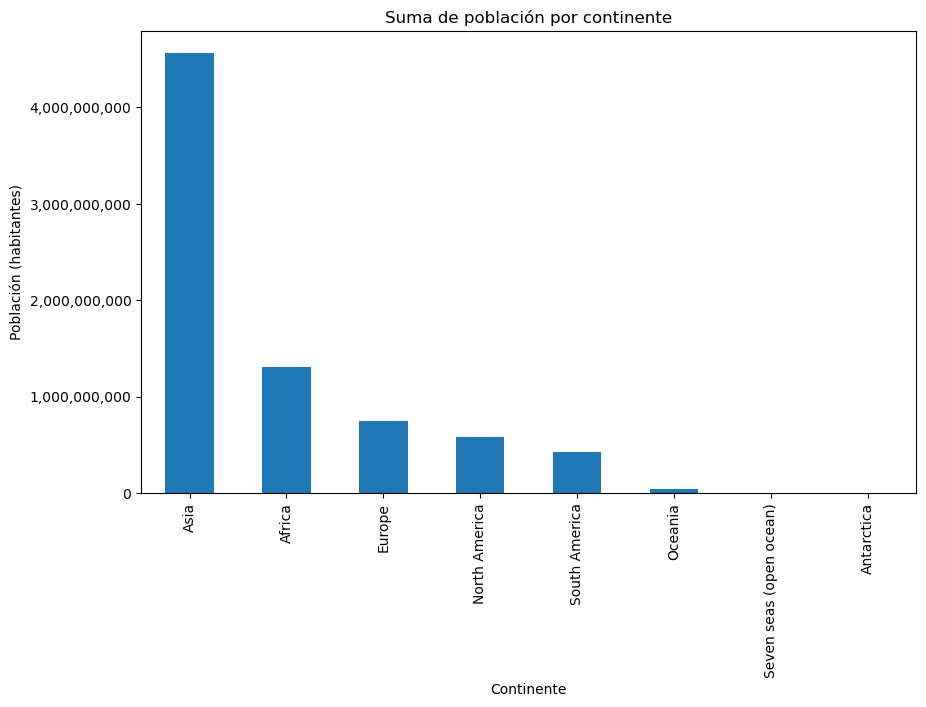
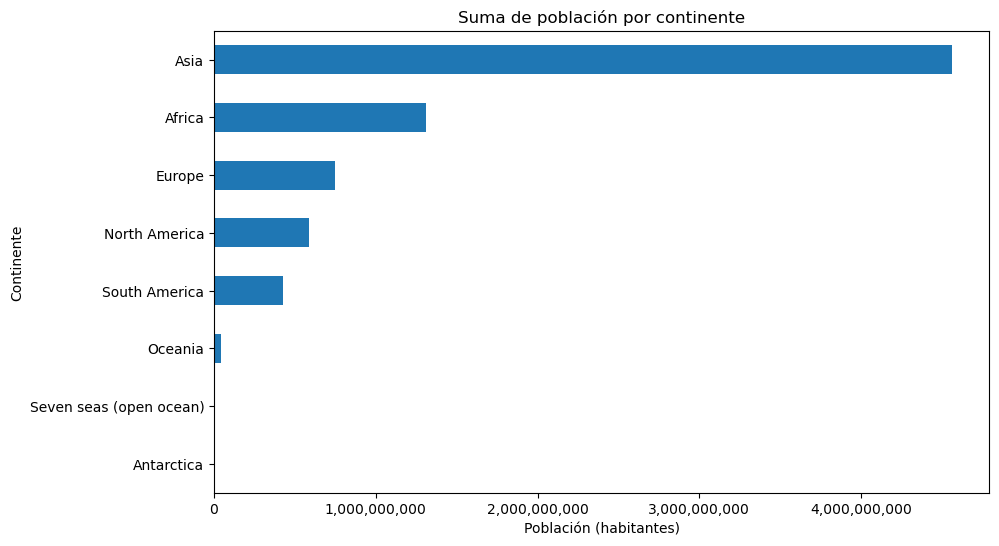
Gráfico de barras horizontales.
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de barras
# Es recomendable que las barras se muestren en orden
poblacion_continente_suma.sort_values(ascending=True).plot.barh(ax=ax)
# Personalización del gráfico
ax.set_title('Suma de población por continente')
ax.set_xlabel('Población (habitantes)')
ax.set_ylabel('Continente')
# Configuración de marcas en los ejes para evitar la notación científica
ax.xaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# Despliegue del gráfico
plt.show()
Suma de población por región y subregión de la ONU#
Barras apiladas#
Con el método pandas.DataFrame.unstack() y el argumento stacked=True puede generarse un gráfico de barras apiladas (en inglés, stacked), el cual permite mostrar datos con varios niveles de agrupación.
# Suma de población por región y subregión de la ONU
poblacion_region_subregion_suma = paises.groupby(['REGION_UN', 'SUBREGION'])['POP_EST'].sum()
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de barras agrupadas
poblacion_region_subregion_suma.unstack().plot.bar(
ax=ax,
stacked=True,
figsize=(10, 6)
)
# Personalización del gráfico
ax.set_title('Suma de población por región y subregión de la ONU')
ax.set_xlabel('Región')
ax.set_ylabel('Población (habitantes)')
# Configuración de marcas en los ejes para evitar la notación científica
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# Ajustar la posición de la leyenda
ax.legend(title='Subregión', bbox_to_anchor=(1.05, 1), loc='upper left')
# Ajustar el diseño para dar más espacio a la leyenda
plt.tight_layout()
# Despliegue del gráfico
plt.show()
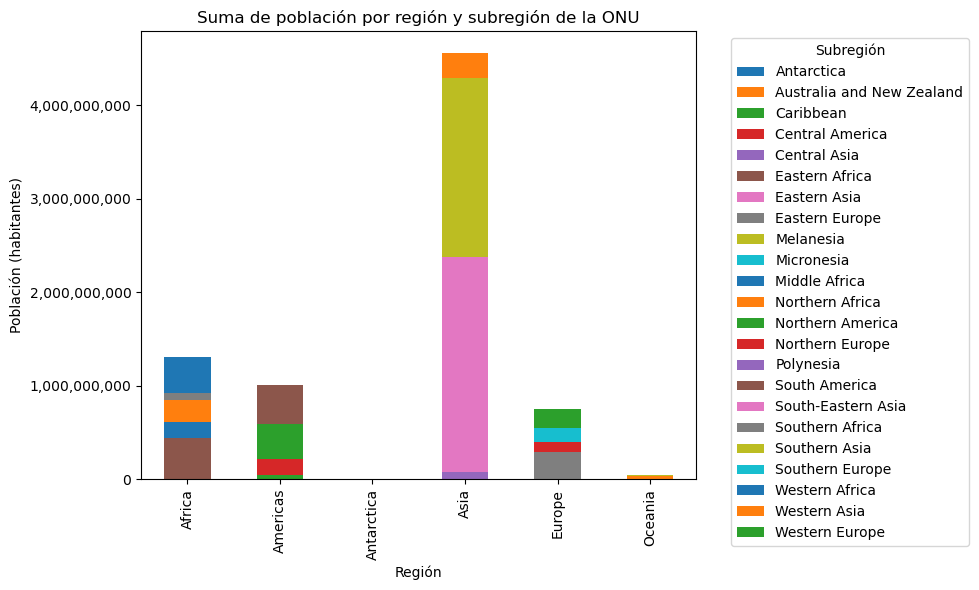
Barras agrupadas#
Otra forma de mostrar barras con diferentes niveles de agrupación son las barras agrupadas, con el argumento stacked=False.
# Suma de población por región y subregión de la ONU
poblacion_region_subregion_suma = paises.groupby(['REGION_UN', 'SUBREGION'])['POP_EST'].sum()
# Creación de una figura con espacio para un gráfico
fig, ax = plt.subplots(figsize=(10, 6))
# Creación del gráfico de barras agrupadas
poblacion_region_subregion_suma.unstack().plot.bar(
ax=ax,
stacked=False,
figsize=(10, 6)
)
# Personalización del gráfico
ax.set_title('Suma de población por región y subregión de la ONU')
ax.set_xlabel('Región')
ax.set_ylabel('Población (habitantes)')
# Configuración de marcas en los ejes para evitar la notación científica
ax.yaxis.set_major_formatter(ticker.StrMethodFormatter('{x:,.0f}'))
# Ajustar la posición de la leyenda
ax.legend(title='Subregión', bbox_to_anchor=(1.05, 1), loc='upper left')
# Ajustar el diseño para dar más espacio a la leyenda
plt.tight_layout()
# Despliegue del gráfico
plt.show()
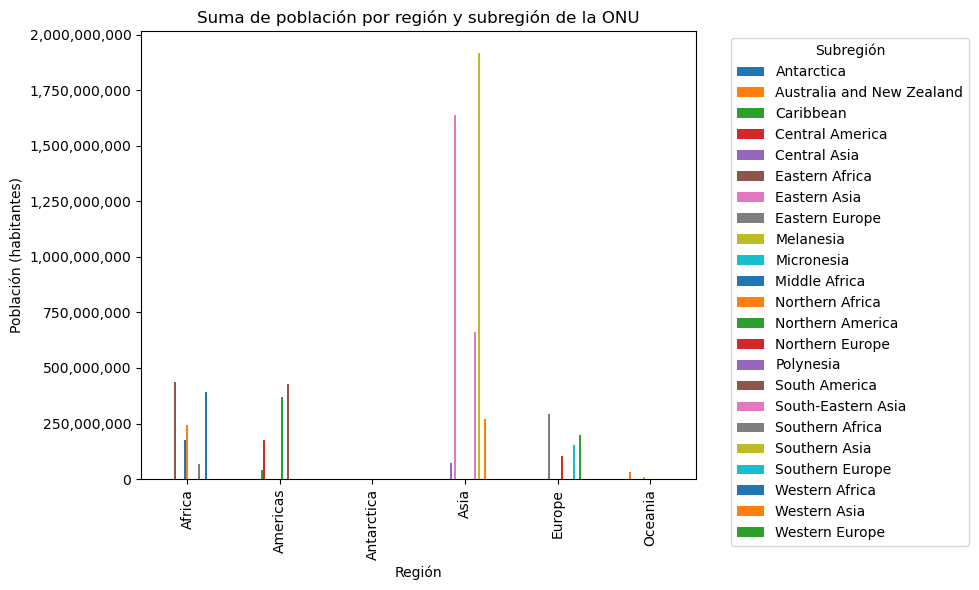
Ejercicios#
Programe gráficos de barras para:
Suma de PIB (
GDP_MD) por economía (ECONOMY).Promedio de PIB per cápita por grupo de ingresos (
INCOME_GRP).
Otros#
Climogramas#
Un climograma es un gráfico estadístico que combina las variables climáticas de temperatura y precitipación a lo largo de un período de tiempo, para una región o lugar específico. Permite visualizar las condiciones climáticas de un área, facilitando el análisis de patrones estacionales y tendencias climáticas.
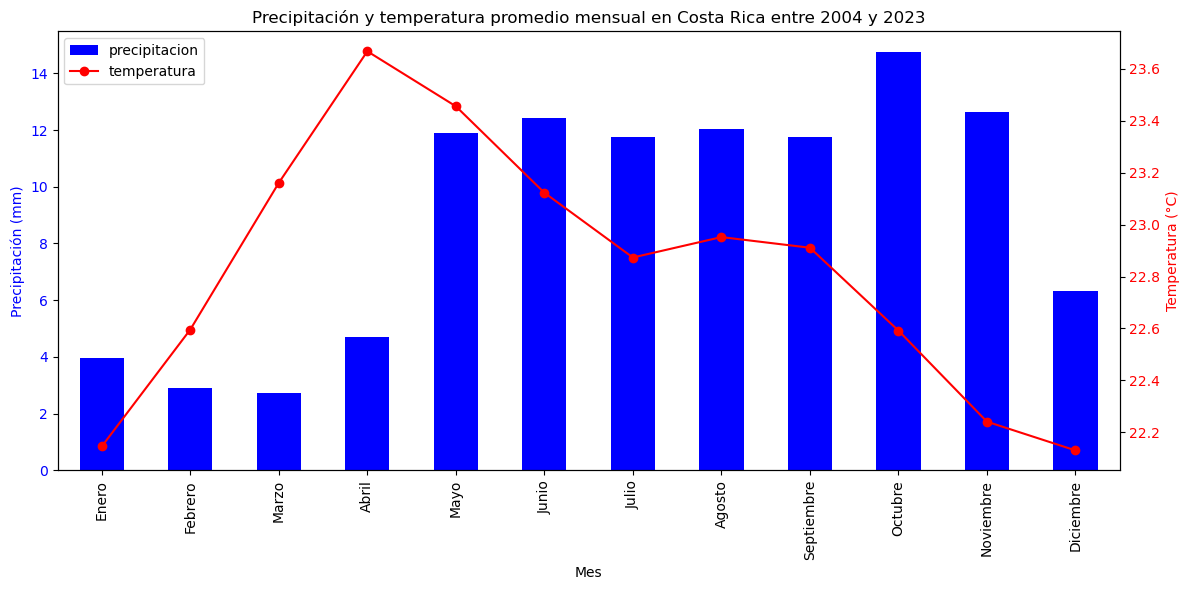
Un climograma puede tomar varias formas. Una de las más usuales es la de un gráfico de barras combinado con un gráfico de líneas. Las barras representan las unidades de tiempo (ej. meses) y su longitud el valor de una de las variables (ej. precipitación), mientras que la línea muestra los valores de la otra variable (ej. temperatura).
En los siguientes bloque de código se genera un climograma con datos de temperatura y precipitación de ERA5. ERA5 es el quinto conjunto de datos de reanálisis atmosférico global producido por el Centro Europeo de Predicción a Medio Plazo (ECMWF). Es una reconstrucción del clima de la Tierra, desde 1950 hasta la actualidad.
Los datos que se utilizan en el climograma corresponden a los promedios mensuales de temperatura a 2 m de la superficie y de precipitación total para todo el territorio de Costa Rica, entre los años 2004 y 2023. Se utilizó una cuadrícula de 0.1 x 0.1 grados decimales.
# Carga de datos de clima
clima = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/era5/temperatura-precipitacion-cri-2004-2023.csv"
)
# Se usa la columna mes como índice
clima.set_index('mes', inplace=True)
# Despliegue de los datos
clima
| temperatura | precipitacion | |
|---|---|---|
| mes | ||
| Enero | 22.15 | 3.98 |
| Febrero | 22.60 | 2.92 |
| Marzo | 23.16 | 2.73 |
| Abril | 23.67 | 4.72 |
| Mayo | 23.46 | 11.91 |
| Junio | 23.12 | 12.44 |
| Julio | 22.87 | 11.75 |
| Agosto | 22.95 | 12.03 |
| Septiembre | 22.91 | 11.77 |
| Octubre | 22.59 | 14.74 |
| Noviembre | 22.24 | 12.65 |
| Diciembre | 22.13 | 6.32 |
# Crear el climograma
fig, ax1 = plt.subplots(figsize=(12, 6))
# Gráfico de barras para precipitación
clima[
['precipitacion']].plot.bar(
ax=ax1,
color='blue',
legend=False
)
ax1.set_xlabel('Mes')
ax1.set_ylabel('Precipitación (mm)', color='blue')
ax1.tick_params(axis='y', labelcolor='blue')
# Gráfico de líneas para la temperatura (comparte los ejes de ax1)
ax2 = ax1.twinx()
clima[['temperatura']].plot(
ax=ax2,
color='red', marker='o',
legend=False
)
ax2.set_ylabel('Temperatura (°C)', color='red')
ax2.tick_params(axis='y', labelcolor='red')
# Título
plt.title('Precipitación y temperatura promedio mensual en Costa Rica entre 2004 y 2023')
# Leyendas
lines, labels = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines + lines2, labels + labels2, loc='upper left')
# Ajustar el diseño para evitar que las etiquetas se corten
plt.tight_layout()
# Mostrar el gráfico
plt.show()