pandas: biblioteca para análisis y manipulación de datos#
![]()
Introducción#
pandas es una biblioteca de Python para análisis y manipulación de datos. Fue creada por Wes McKinney en 2008. El nombre “pandas” puede considerarse un acrónimo de Panel Data o de Python Data Analysis.
Como su estructura principal, pandas implementa el dataframe, el cual es un arreglo rectangular de datos, organizado en filas y columnas. pandas proporciona también una gran cantidad de funciones para limpiar, procesar, analizar y visualizar datos en dataframes.
Carga#
# Carga de pandas con el alias pd
import pandas as pd
Configuración#
El método pandas.set_option() se utiliza para configurar diversas opciones que controlan el comportamiento de pandas y la visualización de datos. Estas opciones permiten personalizar aspectos como:
El número de filas y columnas que se muestran al desplegar conjuntos de datos.
La precisión al mostrar números decimales.
El ancho máximo de filas y columnas.
El formato de la fecha y la hora.
# Configuración de pandas para mostrar separadores de miles y 2 dígitos decimales
# Esto también evita la notación científica
pd.set_option('display.float_format', '{:,.2f}'.format)
Otras funciones relacionadas con la configuración de pandas:
pandas.describe_option(): muestra información sobre una opción (ej.
pd.describe_option('display.max_rows')).pd.describe_option()describe todas las opciones.pandas.get_option(): muestra el valor actual de una opción de configuración (ej.
pd.get_option('display.max_rows')).pandas.reset_option(): reestablece el valor por defecto de una opción de configuración (ej.
pd.reset_option('display.max_rows')).pd.reset_option('all')reestablece todas las opciones.
Debe tenerse en cuenta que el uso de estas funciones aplica para toda una sesión de pandas y no, por ejemplo, para conjuntos de datos específicos.
Estructuras de datos#
Las dos principales estructuras de datos de pandas son las series y los dataframes.
Series#
Las series son arreglos unidimensionales que contienen datos de cualquier tipo.
# Definición de una serie a partir de una lista
lista_primos = [2, 3, 5, 7, 11]
serie_primos = pd.Series(lista_primos)
print(serie_primos)
0 2
1 3
2 5
3 7
4 11
dtype: int64
Al igual que otras estructuras de datos de Python (ej. tuplas, listas), cada elemento de una serie tiene un índice (i.e. una posición). El índice del primer elemento es 0, el del segundo elemento es 1 y así sucesivamente.
# Primer elemento
print("Primer elemento:", serie_primos[0])
# Segundo elemento
print("Segundo elemento:", serie_primos[1])
Primer elemento: 2
Segundo elemento: 3
A diferencia de las tuplas y las listas, las series pueden tener índices no numéricos, a los cuales se les llama etiquetas.
# Índices de una serie con etiquetas personalizadas
serie_primos = pd.Series(lista_primos, index = ["A", "B", "C", "D", "E"])
serie_primos
A 2
B 3
C 5
D 7
E 11
dtype: int64
# Elemento en la posición B
print("Elemento en B:", serie_primos["B"])
# Elemento en la posición D
print("Elemento en D:", serie_primos["D"])
Elemento en B: 3
Elemento en D: 7
Ejercicios
Cree una serie que contenga los montos de ventas de una tienda para los 12 meses del año. Utilice los nombres de los meses como índices.
Dataframes#
Los dataframes son estructuras de datos multidimensionales compuestas por filas y columnas. Un dataframe puede verse como una tabla cuyas columnas se implementan como series.
# Dataframe generado a partir de un diccionario
diccionario_paises = {
"pais": ["PA", "CR", "NI"],
"poblacion": [4246439, 5047561, 6545502]
}
df_paises = pd.DataFrame(diccionario_paises)
df_paises
| pais | poblacion | |
|---|---|---|
| 0 | PA | 4246439 |
| 1 | CR | 5047561 |
| 2 | NI | 6545502 |
La propiedad iloc retorna una o más filas de un dataframe, de acuerdo con un índice o una lista de índices.
# Segunda fila
df_paises.iloc[1]
pais CR
poblacion 5047561
Name: 1, dtype: object
# Segunda y tercera fila
df_paises.loc[[1, 2]]
| pais | poblacion | |
|---|---|---|
| 1 | CR | 5047561 |
| 2 | NI | 6545502 |
Los índices de los dataframes también pueden etiquetarse.
# Dataframe con índices etiquetados
df_paises = pd.DataFrame(diccionario_paises, index=["pais_0", "pais_1", "pais_2"])
df_paises
| pais | poblacion | |
|---|---|---|
| pais_0 | PA | 4246439 |
| pais_1 | CR | 5047561 |
| pais_2 | NI | 6545502 |
La propiedad loc retorna una o más filas de un dataframe, de acuerdo con sus etiquetas.
# Fila en "pais_0"
df_paises.loc["pais_0"]
pais PA
poblacion 4246439
Name: pais_0, dtype: object
Operaciones básicas#
Seguidamente, se describen y ejemplifican algunas de las funciones básicas que pueden realizarse en un dataframe de pandas.
En los siguientes ejemplos, se utilizará un conjunto de datos de países descargado de Natural Earth.
Carga de datos#
El método pandas.read_csv() carga un archivo de valores separados por comas (CSV) en un dataframe.
# Carga de un archivo CSV remoto en un dataframe
paises = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/natural-earth/paises.csv"
)
Ejercicios
Descargue en su computadora el archivo
paises.csvy cárguelo en otro dataframe.
Obtención de información general#
El método pandas.DataFrame.info() despliega un resumen de información sobre un dataframe.
# Información general sobre un dataframe
paises.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 201 entries, 0 to 200
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ADM0_ISO 201 non-null object
1 NAME 201 non-null object
2 CONTINENT 201 non-null object
3 REGION_UN 201 non-null object
4 SUBREGION 201 non-null object
5 REGION_WB 201 non-null object
6 ECONOMY 201 non-null object
7 INCOME_GRP 201 non-null object
8 POP_EST 201 non-null float64
9 GDP_MD 201 non-null int64
dtypes: float64(1), int64(1), object(8)
memory usage: 15.8+ KB
Funciones básicas de recuperación y despliegue de datos#
Los datos contenidos en un dataframe pueden visualizarse con la función print(). En un cuaderno de notas, basta también con ejecutar una celda con el nombre del dataframe. Esta última opción genera una salida más legible.
# Despliegue de los datos de un dataframe
paises
| ADM0_ISO | NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | IDN | Indonesia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 4. Emerging region: MIKT | 4. Lower middle income | 270,625,568.00 | 1119190 |
| 1 | MYS | Malaysia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 6. Developing region | 3. Upper middle income | 31,949,777.00 | 364681 |
| 2 | CHL | Chile | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 18,952,038.00 | 282318 |
| 3 | BOL | Bolivia | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 4. Lower middle income | 11,513,100.00 | 40895 |
| 4 | PER | Peru | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 32,510,453.00 | 226848 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 196 | NRU | Nauru | Oceania | Oceania | Micronesia | East Asia & Pacific | 6. Developing region | 4. Lower middle income | 12,581.00 | 118 |
| 197 | FSM | Micronesia | Oceania | Oceania | Micronesia | East Asia & Pacific | 6. Developing region | 4. Lower middle income | 113,815.00 | 401 |
| 198 | VUT | Vanuatu | Oceania | Oceania | Melanesia | East Asia & Pacific | 7. Least developed region | 4. Lower middle income | 299,882.00 | 934 |
| 199 | PLW | Palau | Oceania | Oceania | Micronesia | East Asia & Pacific | 6. Developing region | 3. Upper middle income | 18,008.00 | 268 |
| 200 | BHR | Bahrain | Asia | Asia | Western Asia | Middle East & North Africa | 6. Developing region | 2. High income: nonOECD | 1,641,172.00 | 38574 |
201 rows × 10 columns
Es posible que la cantidad de filas sea muy grande para desplegarse completamente en la pantalla, por lo que es usual emplear algunos métodos para limitarla.
head() - primeras filas#
El método pandas.DataFrame.head() retorna las primeras n filas de un dataframe (por defecto, n=5).
# Primeras 5 filas de un dataframe
paises.head()
| ADM0_ISO | NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | IDN | Indonesia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 4. Emerging region: MIKT | 4. Lower middle income | 270,625,568.00 | 1119190 |
| 1 | MYS | Malaysia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 6. Developing region | 3. Upper middle income | 31,949,777.00 | 364681 |
| 2 | CHL | Chile | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 18,952,038.00 | 282318 |
| 3 | BOL | Bolivia | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 4. Lower middle income | 11,513,100.00 | 40895 |
| 4 | PER | Peru | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 32,510,453.00 | 226848 |
tail() - últimas filas#
El método pandas.DataFrame.tail() retorna las últimas n filas de un dataframe (por defecto, n=5).
# Últimas 10 filas de un dataframe
paises.tail(10)
| ADM0_ISO | NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 191 | TON | Tonga | Oceania | Oceania | Polynesia | East Asia & Pacific | 6. Developing region | 4. Lower middle income | 104,494.00 | 512 |
| 192 | WSM | Samoa | Oceania | Oceania | Polynesia | East Asia & Pacific | 7. Least developed region | 4. Lower middle income | 197,097.00 | 852 |
| 193 | SLB | Solomon Is. | Oceania | Oceania | Melanesia | East Asia & Pacific | 7. Least developed region | 4. Lower middle income | 669,823.00 | 1589 |
| 194 | TUV | Tuvalu | Oceania | Oceania | Polynesia | East Asia & Pacific | 7. Least developed region | 3. Upper middle income | 11,646.00 | 47 |
| 195 | MDV | Maldives | Seven seas (open ocean) | Asia | Southern Asia | South Asia | 6. Developing region | 3. Upper middle income | 530,953.00 | 5642 |
| 196 | NRU | Nauru | Oceania | Oceania | Micronesia | East Asia & Pacific | 6. Developing region | 4. Lower middle income | 12,581.00 | 118 |
| 197 | FSM | Micronesia | Oceania | Oceania | Micronesia | East Asia & Pacific | 6. Developing region | 4. Lower middle income | 113,815.00 | 401 |
| 198 | VUT | Vanuatu | Oceania | Oceania | Melanesia | East Asia & Pacific | 7. Least developed region | 4. Lower middle income | 299,882.00 | 934 |
| 199 | PLW | Palau | Oceania | Oceania | Micronesia | East Asia & Pacific | 6. Developing region | 3. Upper middle income | 18,008.00 | 268 |
| 200 | BHR | Bahrain | Asia | Asia | Western Asia | Middle East & North Africa | 6. Developing region | 2. High income: nonOECD | 1,641,172.00 | 38574 |
sample() - muestra aleatoria de filas#
El método pandas.DataFrame.sample() retorna una muestra aleatoria de n filas de un dataframe (por defecto, n=1).
# Muestra aleatoria de 3 filas de un dataframe
paises.sample(3)
| ADM0_ISO | NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 104 | PAK | Pakistan | Asia | Asia | Southern Asia | South Asia | 5. Emerging region: G20 | 4. Lower middle income | 216,565,318.00 | 278221 |
| 161 | CYP | Cyprus U.N. Buffer Zone | Asia | Asia | Western Asia | Europe & Central Asia | 6. Developing region | 2. High income: nonOECD | 10,000.00 | 280 |
| 62 | SRB | Kosovo | Europe | Europe | Southern Europe | Europe & Central Asia | 6. Developing region | 4. Lower middle income | 1,794,248.00 | 7926 |
Creación de subconjuntos#
Una de las operaciones más comunes de manipulación y análisis de datos es la creación de subconjuntos. En el caso de un dataframe, estos subconjuntos pueden ser de filas, de columnas o de ambas a la vez. Pueden crearse de varias formas.
Mediante índices numéricos#
La propiedad pandas.DataFrame.iloc permite seleccionar filas y columnas de un dataframe por sus índices numéricos.
Índice de una fila:
# Fila 0
paises.iloc[0]
ADM0_ISO IDN
NAME Indonesia
CONTINENT Asia
REGION_UN Asia
SUBREGION South-Eastern Asia
REGION_WB East Asia & Pacific
ECONOMY 4. Emerging region: MIKT
INCOME_GRP 4. Lower middle income
POP_EST 270,625,568.00
GDP_MD 1119190
Name: 0, dtype: object
Rango de filas:
# Filas entre la 5 (inclusive) y la 7 (inclusive)
paises.iloc[5:8]
| ADM0_ISO | NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 5 | ARG | Argentina | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 44,938,712.00 | 445445 |
| 6 | GBR | United Kingdom | Europe | Europe | Northern Europe | Europe & Central Asia | 1. Developed region: G7 | 1. High income: OECD | 67,366,465.00 | 2863166 |
| 7 | CYP | Cyprus | Asia | Asia | Western Asia | Europe & Central Asia | 6. Developing region | 2. High income: nonOECD | 1,198,575.00 | 24948 |
Lista de índices de filas:
# Filas 3, 5 y 7
paises.iloc[[3, 5, 7]]
| ADM0_ISO | NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|---|
| 3 | BOL | Bolivia | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 4. Lower middle income | 11,513,100.00 | 40895 |
| 5 | ARG | Argentina | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 44,938,712.00 | 445445 |
| 7 | CYP | Cyprus | Asia | Asia | Western Asia | Europe & Central Asia | 6. Developing region | 2. High income: nonOECD | 1,198,575.00 | 24948 |
Mediante etiquetas#
La propiedad pandas.DataFrame.loc permite seleccionar filas y columnas de un dataframe por sus etiquetas.
El método pandas.DataFrame.set_index() crea índices (etiquetas en las filas) para un dataframe con base en columnas existentes.
# Se usa la columna ADM0_ISO como índice
paises.set_index('ADM0_ISO', inplace=True)
paises.iloc[0:5]
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| IDN | Indonesia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 4. Emerging region: MIKT | 4. Lower middle income | 270,625,568.00 | 1119190 |
| MYS | Malaysia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 6. Developing region | 3. Upper middle income | 31,949,777.00 | 364681 |
| CHL | Chile | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 18,952,038.00 | 282318 |
| BOL | Bolivia | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 4. Lower middle income | 11,513,100.00 | 40895 |
| PER | Peru | South America | Americas | South America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 32,510,453.00 | 226848 |
Si se desea reestablecer el índice al numérico predeterminado, puede utilizarse el método pandas.DataFrame.reset_index().
Una vez que se han creado las etiquetas, puede usarse loc para seleccionarlas.
# Fila correspondiente a Costa Rica
paises.loc['CRI']
NAME Costa Rica
CONTINENT North America
REGION_UN Americas
SUBREGION Central America
REGION_WB Latin America & Caribbean
ECONOMY 5. Emerging region: G20
INCOME_GRP 3. Upper middle income
POP_EST 5,047,561.00
GDP_MD 61801
Name: CRI, dtype: object
# Lista de filas correspondientes a Costa Rica, Nicaragua y Panamá
paises.loc[['CRI', 'NIC', 'PAN']]
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| CRI | Costa Rica | North America | Americas | Central America | Latin America & Caribbean | 5. Emerging region: G20 | 3. Upper middle income | 5,047,561.00 | 61801 |
| NIC | Nicaragua | North America | Americas | Central America | Latin America & Caribbean | 6. Developing region | 4. Lower middle income | 6,545,502.00 | 12520 |
| PAN | Panama | North America | Americas | Central America | Latin America & Caribbean | 6. Developing region | 3. Upper middle income | 4,246,439.00 | 66800 |
# Lista de etiquetas de filas y lista de etiquetas de columnas
paises.loc[['CRI', 'NIC', 'PAN'], ['NAME', 'POP_EST']]
| NAME | POP_EST | |
|---|---|---|
| ADM0_ISO | ||
| CRI | Costa Rica | 5,047,561.00 |
| NIC | Nicaragua | 6,545,502.00 |
| PAN | Panama | 4,246,439.00 |
# Nombres y poblaciones de países de América Central
poblaciones_america_central = paises.loc[['PAN', 'CRI', 'NIC', 'HND', 'SLV', 'GTM', 'BLZ'], ['NAME', 'POP_EST']]
poblaciones_america_central
| NAME | POP_EST | |
|---|---|---|
| ADM0_ISO | ||
| PAN | Panama | 4,246,439.00 |
| CRI | Costa Rica | 5,047,561.00 |
| NIC | Nicaragua | 6,545,502.00 |
| HND | Honduras | 9,746,117.00 |
| SLV | El Salvador | 6,453,553.00 |
| GTM | Guatemala | 16,604,026.00 |
| BLZ | Belize | 390,353.00 |
Ejercicios
Seleccione los países de la península ibérica y las columnas correspondientes a sus nombres y a su producto interno bruto.
Mediante expresiones lógicas#
Un dataframe puede filtrarse mediante expresiones lógicas, las cuales pueden incluir los operadores:
Y lógico (AND): &
O lógico (OR): |
No lógico (NOT): ~
# Países con más de 200 millones de habitantes
paises_muy_poblados = paises[paises['POP_EST'] > 200000000]
paises_muy_poblados
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| IDN | Indonesia | Asia | Asia | South-Eastern Asia | East Asia & Pacific | 4. Emerging region: MIKT | 4. Lower middle income | 270,625,568.00 | 1119190 |
| IND | India | Asia | Asia | Southern Asia | South Asia | 3. Emerging region: BRIC | 4. Lower middle income | 1,366,417,754.00 | 2868929 |
| CHN | China | Asia | Asia | Eastern Asia | East Asia & Pacific | 3. Emerging region: BRIC | 3. Upper middle income | 1,405,862,845.00 | 14762473 |
| BRA | Brazil | South America | Americas | South America | Latin America & Caribbean | 3. Emerging region: BRIC | 3. Upper middle income | 211,049,527.00 | 1839758 |
| NGA | Nigeria | Africa | Africa | Western Africa | Sub-Saharan Africa | 5. Emerging region: G20 | 4. Lower middle income | 200,963,599.00 | 448120 |
| PAK | Pakistan | Asia | Asia | Southern Asia | South Asia | 5. Emerging region: G20 | 4. Lower middle income | 216,565,318.00 | 278221 |
| USA | United States of America | North America | Americas | Northern America | North America | 1. Developed region: G7 | 1. High income: OECD | 331,595,460.00 | 21542705 |
# Países con más de 200 millones de habitantes, incluyendo solo NAME, CONTINENT y POP_EST
paises_muy_poblados = paises.loc[paises['POP_EST'] > 200000000, ['NAME', 'CONTINENT', 'POP_EST']]
paises_muy_poblados
| NAME | CONTINENT | POP_EST | |
|---|---|---|---|
| ADM0_ISO | |||
| IDN | Indonesia | Asia | 270,625,568.00 |
| IND | India | Asia | 1,366,417,754.00 |
| CHN | China | Asia | 1,405,862,845.00 |
| BRA | Brazil | South America | 211,049,527.00 |
| NGA | Nigeria | Africa | 200,963,599.00 |
| PAK | Pakistan | Asia | 216,565,318.00 |
| USA | United States of America | North America | 331,595,460.00 |
# Países asiáticos con más de 200 millones de habitantes, incluyendo solo NAME, CONTINENT y POP_EST
paises_asiaticos_muy_poblados = paises.loc[
(paises['POP_EST'] > 200000000) & (paises['CONTINENT'] == 'Asia'),
['NAME', 'CONTINENT', 'POP_EST']
]
paises_asiaticos_muy_poblados
| NAME | CONTINENT | POP_EST | |
|---|---|---|---|
| ADM0_ISO | |||
| IDN | Indonesia | Asia | 270,625,568.00 |
| IND | India | Asia | 1,366,417,754.00 |
| CHN | China | Asia | 1,405,862,845.00 |
| PAK | Pakistan | Asia | 216,565,318.00 |
# Países asiáticos o africanos con más de 200 millones de habitantes, incluyendo solo NAME, CONTINENT y POP_EST
paises_asiaticos_africanos_muy_poblados = paises.loc[
(paises['POP_EST'] > 200000000) & ((paises['CONTINENT'] == 'Asia') | (paises['CONTINENT'] == 'Africa')),
['NAME', 'CONTINENT', 'POP_EST']
]
paises_asiaticos_africanos_muy_poblados
| NAME | CONTINENT | POP_EST | |
|---|---|---|---|
| ADM0_ISO | |||
| IDN | Indonesia | Asia | 270,625,568.00 |
| IND | India | Asia | 1,366,417,754.00 |
| CHN | China | Asia | 1,405,862,845.00 |
| NGA | Nigeria | Africa | 200,963,599.00 |
| PAK | Pakistan | Asia | 216,565,318.00 |
Métodos head(), tail() y sample()#
Los métodos head(), tail() y sample(), descritos anteriormente, también pueden emplearse para crear subconjuntos.
Ejercicios
Cree un subconjunto de los países con producto interno bruto (
GDP_MD) menor a 1000 millones de dólares.Cree un subconjunto de los países con producto interno bruto menor a 1000 millones de dólares y con más de un millón de habitantes.
Cree un subconjunto de los países de América Central, excepto Belice.
Cree un subconjunto de los siete países de América Central y, además, República Dominicana.
Ordenamiento#
El método pandas.DataFrame.sort_values() ordena un dataframe de pandas por una o por varias columnas, en orden ascendente o descendente.
# Ordenamiento ascendente de países por nombre
paises.sort_values(by='NAME')
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| AFG | Afghanistan | Asia | Asia | Southern Asia | South Asia | 7. Least developed region | 5. Low income | 38,041,754.00 | 19291 |
| ALB | Albania | Europe | Europe | Southern Europe | Europe & Central Asia | 6. Developing region | 4. Lower middle income | 2,854,191.00 | 15279 |
| DZA | Algeria | Africa | Africa | Northern Africa | Middle East & North Africa | 6. Developing region | 3. Upper middle income | 43,053,054.00 | 171091 |
| AND | Andorra | Europe | Europe | Southern Europe | Europe & Central Asia | 2. Developed region: nonG7 | 2. High income: nonOECD | 77,142.00 | 3154 |
| AGO | Angola | Africa | Africa | Middle Africa | Sub-Saharan Africa | 7. Least developed region | 3. Upper middle income | 31,825,295.00 | 88815 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| B28 | W. Sahara | Africa | Africa | Northern Africa | Middle East & North Africa | 7. Least developed region | 5. Low income | 603,253.00 | 907 |
| YEM | Yemen | Asia | Asia | Western Asia | Middle East & North Africa | 7. Least developed region | 4. Lower middle income | 29,161,922.00 | 22581 |
| ZMB | Zambia | Africa | Africa | Eastern Africa | Sub-Saharan Africa | 7. Least developed region | 4. Lower middle income | 17,861,030.00 | 23309 |
| ZWE | Zimbabwe | Africa | Africa | Eastern Africa | Sub-Saharan Africa | 5. Emerging region: G20 | 5. Low income | 14,645,468.00 | 21440 |
| SWZ | eSwatini | Africa | Africa | Southern Africa | Sub-Saharan Africa | 6. Developing region | 4. Lower middle income | 1,148,130.00 | 4471 |
201 rows × 9 columns
# Ordenamiento ascendente de países por nombre y despliegue de las 5 primeras filas
paises.sort_values(by='NAME').head()
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| AFG | Afghanistan | Asia | Asia | Southern Asia | South Asia | 7. Least developed region | 5. Low income | 38,041,754.00 | 19291 |
| ALB | Albania | Europe | Europe | Southern Europe | Europe & Central Asia | 6. Developing region | 4. Lower middle income | 2,854,191.00 | 15279 |
| DZA | Algeria | Africa | Africa | Northern Africa | Middle East & North Africa | 6. Developing region | 3. Upper middle income | 43,053,054.00 | 171091 |
| AND | Andorra | Europe | Europe | Southern Europe | Europe & Central Asia | 2. Developed region: nonG7 | 2. High income: nonOECD | 77,142.00 | 3154 |
| AGO | Angola | Africa | Africa | Middle Africa | Sub-Saharan Africa | 7. Least developed region | 3. Upper middle income | 31,825,295.00 | 88815 |
# Ordenamiento descendente de países por nombre y despliegue de las 5 primeras filas
paises.sort_values(by='NAME', ascending=False).head()
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | |
|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | |||||||||
| SWZ | eSwatini | Africa | Africa | Southern Africa | Sub-Saharan Africa | 6. Developing region | 4. Lower middle income | 1,148,130.00 | 4471 |
| ZWE | Zimbabwe | Africa | Africa | Eastern Africa | Sub-Saharan Africa | 5. Emerging region: G20 | 5. Low income | 14,645,468.00 | 21440 |
| ZMB | Zambia | Africa | Africa | Eastern Africa | Sub-Saharan Africa | 7. Least developed region | 4. Lower middle income | 17,861,030.00 | 23309 |
| YEM | Yemen | Asia | Asia | Western Asia | Middle East & North Africa | 7. Least developed region | 4. Lower middle income | 29,161,922.00 | 22581 |
| B28 | W. Sahara | Africa | Africa | Northern Africa | Middle East & North Africa | 7. Least developed region | 5. Low income | 603,253.00 | 907 |
# Ordenamiento de países por continente y nombre
paises.sort_values(by=['CONTINENT', 'NAME'], ascending=[True, True])[['CONTINENT', 'NAME']]
| CONTINENT | NAME | |
|---|---|---|
| ADM0_ISO | ||
| DZA | Africa | Algeria |
| AGO | Africa | Angola |
| BEN | Africa | Benin |
| BWA | Africa | Botswana |
| BFA | Africa | Burkina Faso |
| ... | ... | ... |
| PRY | South America | Paraguay |
| PER | South America | Peru |
| SUR | South America | Suriname |
| URY | South America | Uruguay |
| VEN | South America | Venezuela |
201 rows × 2 columns
Ejercicios
Cree un subconjunto de todos los países del mundo ordenado descendentemente por la cantidad de habitantes.
Cree un subconjunto de todos los países del mundo ordenado ascendentemente por el producto interno bruto.
Creación y modificación de columnas#
En un dataframe, pueden crearse o modificarse columnas de varias formas. Una de las más comunes es a través de operaciones con otras columnas.
Ejemplo: PIB per cápita#
En el dataframe paises puede crearse una nueva columna llamada GDP_MD_PC con el resultado del cálculo del Producto Interno Bruto (PIB) per cápita para cada país.
# Creación de la columna GDP_PC (PIB per cápita en dólares)
paises['GDP_PC'] = (paises['GDP_MD'] * 1000000) / paises['POP_EST']
Para modularizar el código, es conveniente crear una función que realice el cálculo del PIB per cápita.
def pib_per_capita(pib, poblacion):
"""
Retorna el PIB per cápita dados el PIB de un país (en millones de dólares) y su población.
"""
return (pib * 1000000) / poblacion
# Creación de la columna GDP_PC (PIB per cápita en dólares)
# mediante la función pib_per_capita()
paises['GDP_PC'] = pib_per_capita(paises['GDP_MD'], paises['POP_EST'])
# Despliegue de la nueva columna
paises[['NAME', 'GDP_MD', 'POP_EST', 'GDP_PC']]
| NAME | GDP_MD | POP_EST | GDP_PC | |
|---|---|---|---|---|
| ADM0_ISO | ||||
| IDN | Indonesia | 1119190 | 270,625,568.00 | 4,135.57 |
| MYS | Malaysia | 364681 | 31,949,777.00 | 11,414.20 |
| CHL | Chile | 282318 | 18,952,038.00 | 14,896.45 |
| BOL | Bolivia | 40895 | 11,513,100.00 | 3,552.04 |
| PER | Peru | 226848 | 32,510,453.00 | 6,977.69 |
| ... | ... | ... | ... | ... |
| NRU | Nauru | 118 | 12,581.00 | 9,379.22 |
| FSM | Micronesia | 401 | 113,815.00 | 3,523.26 |
| VUT | Vanuatu | 934 | 299,882.00 | 3,114.56 |
| PLW | Palau | 268 | 18,008.00 | 14,882.27 |
| BHR | Bahrain | 38574 | 1,641,172.00 | 23,503.93 |
201 rows × 4 columns
Ejemplo: idiomas oficiales#
Para crear una nueva columna llamada LANGUAGES, con los idiomas oficiales de cada país, se define una función llamada obtener_idiomas_pais(), la cual recibe como entrada el código ISO 3166-1 alpha-3 (cca3) del país (el cual se encuentra en el índice del dataframe paises) y consulta el API REST Countries para retornar una hilera de texto con los nombres de los idiomas.
import requests
def obtener_idiomas_pais(cca3):
"""
Obtiene una cadena con la lista de lenguajes oficiales de un país dado su código cca3.
"""
# URL del API REST Countries
url = f'https://restcountries.com/v3.1/alpha/{cca3}'
# Respuesta del API a la solicitud
respuesta = requests.get(url)
# Revisión de la respuesta
if respuesta.status_code == 200:
datos = respuesta.json()
if datos and 'languages' in datos[0]:
lenguajes = datos[0]['languages']
lista_lenguajes = list(lenguajes.values())
return ', '.join(lista_lenguajes)
else:
return None
else:
return None
Ahora, para crear o modificar la nueva columna LANGUAGES, se utiliza la función map() de Python, la cual aplica una función a cada uno de los elementos de una estructura de datos iterable (ej. tuplas, listas, series, dataframes). En este caso, aplica la función obtener_idiomas_pais() al dataframe de países, recibiendo como entrada el índice del dataframe paises (paises.index).
# Creación de la columna LANGUAGES mediante la función obtener_idiomas_pais()
paises['LANGUAGES'] = paises.index.map(obtener_idiomas_pais)
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[39], line 2
1 # Creación de la columna LANGUAGES mediante la función obtener_idiomas_pais()
----> 2 paises['LANGUAGES'] = paises.index.map(obtener_idiomas_pais)
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/pandas/core/indexes/base.py:6491, in Index.map(self, mapper, na_action)
6455 """
6456 Map values using an input mapping or function.
6457
(...)
6487 Index(['A', 'B', 'C'], dtype='object')
6488 """
6489 from pandas.core.indexes.multi import MultiIndex
-> 6491 new_values = self._map_values(mapper, na_action=na_action)
6493 # we can return a MultiIndex
6494 if new_values.size and isinstance(new_values[0], tuple):
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/pandas/core/base.py:921, in IndexOpsMixin._map_values(self, mapper, na_action, convert)
918 if isinstance(arr, ExtensionArray):
919 return arr.map(mapper, na_action=na_action)
--> 921 return algorithms.map_array(arr, mapper, na_action=na_action, convert=convert)
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/pandas/core/algorithms.py:1743, in map_array(arr, mapper, na_action, convert)
1741 values = arr.astype(object, copy=False)
1742 if na_action is None:
-> 1743 return lib.map_infer(values, mapper, convert=convert)
1744 else:
1745 return lib.map_infer_mask(
1746 values, mapper, mask=isna(values).view(np.uint8), convert=convert
1747 )
File lib.pyx:2972, in pandas._libs.lib.map_infer()
Cell In[38], line 12, in obtener_idiomas_pais(cca3)
9 url = f'https://restcountries.com/v3.1/alpha/{cca3}'
11 # Respuesta del API a la solicitud
---> 12 respuesta = requests.get(url)
14 # Revisión de la respuesta
15 if respuesta.status_code == 200:
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/requests/api.py:73, in get(url, params, **kwargs)
62 def get(url, params=None, **kwargs):
63 r"""Sends a GET request.
64
65 :param url: URL for the new :class:`Request` object.
(...)
70 :rtype: requests.Response
71 """
---> 73 return request("get", url, params=params, **kwargs)
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/requests/api.py:59, in request(method, url, **kwargs)
55 # By using the 'with' statement we are sure the session is closed, thus we
56 # avoid leaving sockets open which can trigger a ResourceWarning in some
57 # cases, and look like a memory leak in others.
58 with sessions.Session() as session:
---> 59 return session.request(method=method, url=url, **kwargs)
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/requests/sessions.py:589, in Session.request(self, method, url, params, data, headers, cookies, files, auth, timeout, allow_redirects, proxies, hooks, stream, verify, cert, json)
584 send_kwargs = {
585 "timeout": timeout,
586 "allow_redirects": allow_redirects,
587 }
588 send_kwargs.update(settings)
--> 589 resp = self.send(prep, **send_kwargs)
591 return resp
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/requests/sessions.py:703, in Session.send(self, request, **kwargs)
700 start = preferred_clock()
702 # Send the request
--> 703 r = adapter.send(request, **kwargs)
705 # Total elapsed time of the request (approximately)
706 elapsed = preferred_clock() - start
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/requests/adapters.py:667, in HTTPAdapter.send(self, request, stream, timeout, verify, cert, proxies)
664 timeout = TimeoutSauce(connect=timeout, read=timeout)
666 try:
--> 667 resp = conn.urlopen(
668 method=request.method,
669 url=url,
670 body=request.body,
671 headers=request.headers,
672 redirect=False,
673 assert_same_host=False,
674 preload_content=False,
675 decode_content=False,
676 retries=self.max_retries,
677 timeout=timeout,
678 chunked=chunked,
679 )
681 except (ProtocolError, OSError) as err:
682 raise ConnectionError(err, request=request)
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/urllib3/connectionpool.py:789, in HTTPConnectionPool.urlopen(self, method, url, body, headers, retries, redirect, assert_same_host, timeout, pool_timeout, release_conn, chunked, body_pos, preload_content, decode_content, **response_kw)
786 response_conn = conn if not release_conn else None
788 # Make the request on the HTTPConnection object
--> 789 response = self._make_request(
790 conn,
791 method,
792 url,
793 timeout=timeout_obj,
794 body=body,
795 headers=headers,
796 chunked=chunked,
797 retries=retries,
798 response_conn=response_conn,
799 preload_content=preload_content,
800 decode_content=decode_content,
801 **response_kw,
802 )
804 # Everything went great!
805 clean_exit = True
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/urllib3/connectionpool.py:466, in HTTPConnectionPool._make_request(self, conn, method, url, body, headers, retries, timeout, chunked, response_conn, preload_content, decode_content, enforce_content_length)
463 try:
464 # Trigger any extra validation we need to do.
465 try:
--> 466 self._validate_conn(conn)
467 except (SocketTimeout, BaseSSLError) as e:
468 self._raise_timeout(err=e, url=url, timeout_value=conn.timeout)
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/urllib3/connectionpool.py:1095, in HTTPSConnectionPool._validate_conn(self, conn)
1093 # Force connect early to allow us to validate the connection.
1094 if conn.is_closed:
-> 1095 conn.connect()
1097 # TODO revise this, see https://github.com/urllib3/urllib3/issues/2791
1098 if not conn.is_verified and not conn.proxy_is_verified:
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/urllib3/connection.py:615, in HTTPSConnection.connect(self)
613 def connect(self) -> None:
614 sock: socket.socket | ssl.SSLSocket
--> 615 self.sock = sock = self._new_conn()
616 server_hostname: str = self.host
617 tls_in_tls = False
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/urllib3/connection.py:196, in HTTPConnection._new_conn(self)
191 """Establish a socket connection and set nodelay settings on it.
192
193 :return: New socket connection.
194 """
195 try:
--> 196 sock = connection.create_connection(
197 (self._dns_host, self.port),
198 self.timeout,
199 source_address=self.source_address,
200 socket_options=self.socket_options,
201 )
202 except socket.gaierror as e:
203 raise NameResolutionError(self.host, self, e) from e
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/site-packages/urllib3/util/connection.py:60, in create_connection(address, timeout, source_address, socket_options)
57 except UnicodeError:
58 raise LocationParseError(f"'{host}', label empty or too long") from None
---> 60 for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
61 af, socktype, proto, canonname, sa = res
62 sock = None
File ~/miniconda3/envs/gf0657-2024-ii/lib/python3.12/socket.py:976, in getaddrinfo(host, port, family, type, proto, flags)
973 # We override this function since we want to translate the numeric family
974 # and socket type values to enum constants.
975 addrlist = []
--> 976 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
977 af, socktype, proto, canonname, sa = res
978 addrlist.append((_intenum_converter(af, AddressFamily),
979 _intenum_converter(socktype, SocketKind),
980 proto, canonname, sa))
KeyboardInterrupt:
# Despliegue de la nueva columna
paises[['NAME', 'LANGUAGES']]
| NAME | LANGUAGES | |
|---|---|---|
| ADM0_ISO | ||
| IDN | Indonesia | Indonesian |
| MYS | Malaysia | English, Malay |
| CHL | Chile | Spanish |
| BOL | Bolivia | Aymara, Guaraní, Quechua, Spanish |
| PER | Peru | Aymara, Quechua, Spanish |
| ... | ... | ... |
| NRU | Nauru | English, Nauru |
| FSM | Micronesia | English |
| VUT | Vanuatu | Bislama, English, French |
| PLW | Palau | English, Palauan |
| BHR | Bahrain | Arabic |
201 rows × 2 columns
Ejercicios
Defina una función llamada
obtener_capital_pais()que reciba el código cca3 de un país y retorne su capital mediante una consulta al API REST Countries. Utilíce esta función para crear en el dataframepaisesuna nueva columna llamadaCAPITAL, con la ciudad capital de cada país.
Agrupación y agregación#
El proceso de agrupación y agregación consiste en dividir un conjunto de datos en grupos basados en uno o más criterios, para luego realizar operaciones en cada grupo. En pandas, este proceso se realiza mediante el método pandas.DataFrame.groupby().
Por ejemplo, el dataframe de países puede agruparse por continente para calcular en cada uno la suma de la población.
# Suma de población por continente
suma_poblacion_por_continente = paises.groupby('CONTINENT')['POP_EST'].sum()
# Despliegue de los resultados, ordenados descendentemente por población
suma_poblacion_por_continente.sort_values(ascending=False)
CONTINENT
Asia 4,562,304,603.00
Africa 1,307,986,092.30
Europe 747,708,092.00
North America 584,776,221.00
South America 427,063,263.00
Oceania 41,589,500.00
Seven seas (open ocean) 1,894,289.00
Antarctica 4,490.00
Name: POP_EST, dtype: float64
El argumento de groupby() es usualmente una columna categórica (ej. CONTINENT) cuyos valores pasan a ser los grupos. En cada grupo se aplica una función de agregación (ej. sum()) para los valores de una columna numérica (ej. POP_EST).
Algunas funciones comunes de agregación son:
sum(): suma.mean(): promedio.count(): número de elementos.max(),min(): valores máximo y mínimo.median(): mediana.std(): desviación estándar.agg(): para aplicar múltiples funciones o funciones personalizadas.
El métoddo groupby() permite agrupar también por múltiples columnas.
# Suma de población por región y subregión de la ONU
suma_poblacion_por_region_subregion = paises.groupby(['REGION_UN', 'SUBREGION'])['POP_EST'].sum()
suma_poblacion_por_region_subregion
REGION_UN SUBREGION
Africa Eastern Africa 435,175,445.30
Middle Africa 174,308,432.00
Northern Africa 241,801,558.00
Southern Africa 66,629,895.00
Western Africa 391,434,098.00
Americas Caribbean 38,982,419.00
Central America 176,609,080.00
Northern America 369,184,722.00
South America 427,063,263.00
Antarctica Antarctica 4,490.00
Asia Central Asia 73,814,587.00
Eastern Asia 1,636,296,580.00
South-Eastern Asia 661,911,038.00
Southern Asia 1,918,690,648.00
Western Asia 272,122,703.00
Europe Eastern Europe 291,080,093.00
Northern Europe 105,802,448.00
Southern Europe 152,729,852.00
Western Europe 198,095,699.00
Oceania Australia and New Zealand 30,319,695.00
Melanesia 10,635,767.00
Micronesia 320,801.00
Polynesia 313,237.00
Name: POP_EST, dtype: float64
También es posible aplicar múltiples funciones de agregación.
# Suma y promedio de población por región y subregión de la ONU
suma_promedio_poblacion_por_region_subregion = paises.groupby(['REGION_UN', 'SUBREGION'])['POP_EST'].agg(['sum', 'mean'])
suma_promedio_poblacion_por_region_subregion
| sum | mean | ||
|---|---|---|---|
| REGION_UN | SUBREGION | ||
| Africa | Eastern Africa | 435,175,445.30 | 22,903,970.81 |
| Middle Africa | 174,308,432.00 | 19,367,603.56 | |
| Northern Africa | 241,801,558.00 | 34,543,079.71 | |
| Southern Africa | 66,629,895.00 | 13,325,979.00 | |
| Western Africa | 391,434,098.00 | 24,464,631.12 | |
| Americas | Caribbean | 38,982,419.00 | 2,998,647.62 |
| Central America | 176,609,080.00 | 22,076,135.00 | |
| Northern America | 369,184,722.00 | 184,592,361.00 | |
| South America | 427,063,263.00 | 35,588,605.25 | |
| Antarctica | Antarctica | 4,490.00 | 4,490.00 |
| Asia | Central Asia | 73,814,587.00 | 14,762,917.40 |
| Eastern Asia | 1,636,296,580.00 | 272,716,096.67 | |
| South-Eastern Asia | 661,911,038.00 | 60,173,730.73 | |
| Southern Asia | 1,918,690,648.00 | 213,187,849.78 | |
| Western Asia | 272,122,703.00 | 14,322,247.53 | |
| Europe | Eastern Europe | 291,080,093.00 | 29,108,009.30 |
| Northern Europe | 105,802,448.00 | 10,580,244.80 | |
| Southern Europe | 152,729,852.00 | 9,545,615.75 | |
| Western Europe | 198,095,699.00 | 22,010,633.22 | |
| Oceania | Australia and New Zealand | 30,319,695.00 | 15,159,847.50 |
| Melanesia | 10,635,767.00 | 2,658,941.75 | |
| Micronesia | 320,801.00 | 64,160.20 | |
| Polynesia | 313,237.00 | 104,412.33 |
Ejercicios
Calcule el promedio del PIB (
GDP_MD) por continente. Muestre los resultados por orden alfabético de continente.Calcule la suma y el promedio del PIB (
GDP_MD) por continente. Muestre los resultados por orden descendente de suma del PIB.Calcule el promedio del PIB (
GDP_MD) por grupo de ingresos (INCOME_GRP). Muestre los resultados en orden descendente de promedio del PIB.Calcule el promedio del PIB (
GDP_MD) para las subregiones de las regiones de la ONU del continente americano. Muestre los resultados en orden descendente de promedio del PIB.
Unión (join)#
La unión (en inglés, join) de datos ubicados en diferentes fuentes (ej. diferentes archivos) es una tarea común en análisis de información. Las uniones pueden ser de filas, columnas o de ambas. Usualmente, este tipo de operaciones se realiza con base en columnas que son comunes en los conjuntos de datos que se desea unir. A estas columnas se les llama “llaves” o “claves” (en inglés, keys).
Hay varios tipos de uniones de datos:
Left join: mantiene todas las filas del conjunto de datos del lado izquierdo y les agrega las columnas del conjunto de datos del lado derecho, en las filas en las que hay coincidencia en las llaves.
Right join: mantiene todas las filas del conjunto de datos del lado derecho y agrega las columnas del conjunto de datos del lado izquierdo, en las filas en las que hay coincidencia en las llaves.
Inner join: incluye las filas que coinciden en ambos conjuntos de datos.
Full join: incluye todas las filas de ambos conjuntos de datos.
Los diferentes tipos de unión se ilustran en la Fig. 24 mediante diagramas de Venn.
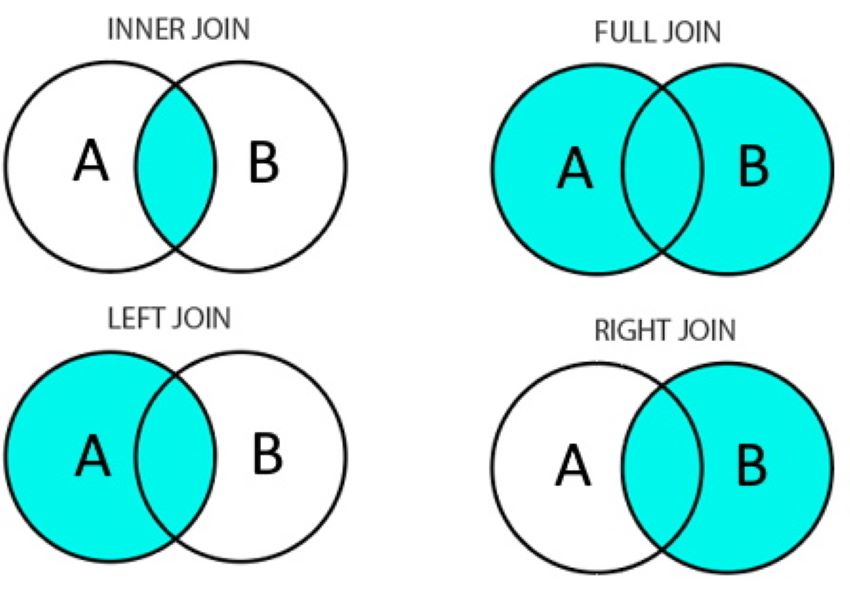
Fig. 24 Tipos de uniones de datos. Imagen de hostingplus.#
La biblioteca pandas incluye varios métodos para unir series y dataframes:
Para ejemplificar el concepto de unión de datos, al dataframe paises se le agregará una columna correspondiente a la esperanza de vida al nacer en cada país. Esta columna proviene de los datos de indicadores del Banco Mundial.
# Carga de datos de esperanza de vida al nacer por país
esperanza_vida = pd.read_csv(
"https://raw.githubusercontent.com/gf0657-programacionsig/2024-ii/refs/heads/main/datos/world-bank/paises-esperanza-vida.csv"
)
El archivo CSV del Banco Mundial tiene más de 60 columnas. Para simplificar el análisis, se conservan solamente las columnas Country Code (código cca3) y 2022 (esperanza de vida al nacer en 2022). La primera se utiliza como índice.
# Reducción de columnas de esperanza_vida
esperanza_vida = esperanza_vida[['Country Code', '2022']]
# Se usa la columna 'Country Code' como índice
esperanza_vida.set_index('Country Code', inplace=True)
# Muestra de los datos
esperanza_vida.sample(10)
| 2022 | |
|---|---|
| Country Code | |
| IBT | 70.51 |
| NPL | 70.48 |
| MNA | 72.30 |
| LCA | 71.29 |
| ECA | 74.11 |
| PAK | 66.43 |
| ISL | 82.17 |
| IDA | 64.05 |
| OMN | 73.94 |
| ARB | 71.23 |
Seguidamente, se utiliza el método pandas.Dataframe.join() para unir paises con paises_esperanza_vida. Se elige este método debido a que su sintaxis es muy sencilla cuando las llaves de ambos dataframes con los índices.
# Unión de los dataframes paises y esperanza_vida
paises = paises.join(esperanza_vida, how="left")
En este caso paises es el conjunto del “lado izquierdo” y esperanza_vida el del “lado derecho”. El argumento how="left" indica que se está realizando un left join, por lo que se conservan todas las filas del conjunto de lado izquierdo. Si el código cca3 de algún país de países no está en esperanza_vida, la columna unida tendrá un valor nulo.
La nueva columna se renombra con el método pandas.DataFrame.rename(), para que sea similar a las otras.
# Cambio de nombre de la nueva columna
paises.rename(columns={'2022': 'LIFE_EXPECTANCY'}, inplace=True)
# Muestra aleatoria de 10 filas
paises.sample(5)
| NAME | CONTINENT | REGION_UN | SUBREGION | REGION_WB | ECONOMY | INCOME_GRP | POP_EST | GDP_MD | GDP_PC | LANGUAGES | LIFE_EXPECTANCY | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADM0_ISO | ||||||||||||
| IRL | Ireland | Europe | Europe | Northern Europe | Europe & Central Asia | 2. Developed region: nonG7 | 1. High income: OECD | 4,941,444.00 | 388698 | 78,660.81 | English, Irish | 83.06 |
| MOZ | Mozambique | Africa | Africa | Eastern Africa | Sub-Saharan Africa | 7. Least developed region | 5. Low income | 30,366,036.00 | 15291 | 503.56 | Portuguese | 59.62 |
| CPV | Cabo Verde | Africa | Africa | Western Africa | Sub-Saharan Africa | 6. Developing region | 4. Lower middle income | 549,935.00 | 1981 | 3,602.24 | Portuguese | 74.72 |
| JAM | Jamaica | North America | Americas | Caribbean | Latin America & Caribbean | 6. Developing region | 3. Upper middle income | 2,948,279.00 | 16458 | 5,582.24 | English, Jamaican Patois | 70.63 |
| BHS | Bahamas | North America | Americas | Caribbean | Latin America & Caribbean | 6. Developing region | 2. High income: nonOECD | 389,482.00 | 13578 | 34,861.69 | English | 74.36 |
# Países con esperanza de vida más alta
paises.sort_values(by='LIFE_EXPECTANCY', ascending=False).head(10)[['NAME', 'CONTINENT', 'LIFE_EXPECTANCY']]
| NAME | CONTINENT | LIFE_EXPECTANCY | |
|---|---|---|---|
| ADM0_ISO | |||
| LIE | Liechtenstein | Europe | 84.32 |
| JPN | Japan | Asia | 84.00 |
| CHE | Switzerland | Europe | 83.45 |
| AUS | Australia | Oceania | 83.20 |
| SWE | Sweden | Europe | 83.11 |
| ESP | Spain | Europe | 83.08 |
| IRL | Ireland | Europe | 83.06 |
| LUX | Luxembourg | Europe | 83.05 |
| ITA | Italy | Europe | 82.90 |
| SGP | Singapore | Asia | 82.90 |
# Países con esperanza de vida más baja
paises.sort_values(by='LIFE_EXPECTANCY', ascending=True).head(10)[['NAME', 'CONTINENT', 'LIFE_EXPECTANCY']]
| NAME | CONTINENT | LIFE_EXPECTANCY | |
|---|---|---|---|
| ADM0_ISO | |||
| TCD | Chad | Africa | 53.00 |
| LSO | Lesotho | Africa | 53.04 |
| NGA | Nigeria | Africa | 53.63 |
| CAF | Central African Rep. | Africa | 54.48 |
| SSD | S. Sudan | Africa | 55.57 |
| SOM | Somaliland | Africa | 56.11 |
| SOM | Somalia | Africa | 56.11 |
| SWZ | eSwatini | Africa | 56.36 |
| NAM | Namibia | Africa | 58.06 |
| CIV | Côte d'Ivoire | Africa | 58.92 |
Ejercicios
Mediante uniones de datos, agregue al dataframe
paisescolumnas correspondientes a:
Tasa de alfabetización de adultos.
Tasa de mortalidad infantil.
Busque los archivos de datos necesarios en Banco Mundial - Datos de indicadores. Sugerencia: con un editor de texto (ej. VS Code) elimine las filas que no forman parte del formato CSV en la parte superior de los archivos.
Exportación#
pandas proporciona varios métodos para exportar dataframes a otros formatos. Por ejemplo, el método pandas.DataFrame.to_csv() exporta un dataframe a un archivo de valores separados por comas (CSV). Otros métodos similares pueden exportar a otros formatos.
# Exportación al formato CSV
paises.to_csv('paises-ampliado.csv')
# Exportación al formato JSON
paises.to_json('paises-ampliado.json', orient='records')
Recursos de interés#
Banco Mundial - Datos de indicadores. (s. f.). Recuperado 6 de octubre de 2024, de https://datos.bancomundial.org/indicador
Natural Earth - Free vector and raster map data. (s. f.). Recuperado 6 de octubre de 2024, de https://www.naturalearthdata.com/