Visualización de datos con matplotlib y seaborn
Contents
Visualización de datos con matplotlib y seaborn#
Descripción general#
matplotlib es una biblioteca para crear visualizaciones de datos estáticas, animadas e interactivas en Python. Su desarrollo fue liderado por John D. Hunter y Michael Droettboom. Su primera versión se liberó en 2003. Le brinda al programador control sobre todos los detalles de un gráfico estadístico. El módulo pyplot, uno de los más populares de matplotlib, proporciona una interfaz de programación similar a la de MATLAB. matplotlib es una de las bibliotecas más populares de graficación de Python y puede trabajar independientemente o de manera integrada con pandas.
seaborn es otra biblioteca para visualización de datos. Implementa una interfaz de alto nivel para matplotlib, con el objetivo de hacerla más fácil de utilizar y mejorar el estilo (colores, formas, etc.) de los gráficos estadísticos.
Instalación de las bibliotecas#
Ambas bibliotecas pueden instalarse con pip, conda o mamba, desde la línea de comandos del sistema operativo.
Instalación de matplotlib:
# Con pip:
pip install matplotlib
# Con conda:
conda install matplotlib -c conda-forge
# Con mamba:
mamba install matplotlib -c conda-forge
Instalación de seaborn:
# Con pip:
pip install seaborn
# Con conda:
conda install seaborn -c conda-forge
# Con mamba:
mamba install seaborn -c conda-forge
Carga de las bibliotecas#
# Carga de módulos de matplotlib
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
# Carga de seaborn
import seaborn as sns
# Carga de pandas
import pandas as pd
Conjuntos de datos para pruebas#
Casos de COVID-19 en Costa Rica#
Estos datos son publicados por el Ministerio de Salud de Costa Rica en https://geovision.uned.ac.cr/oges/. Se distribuyen en archivos CSV, incluyendo un archivo de datos generales para todo el país y varios archivos con datos por cantón. La fecha de la última actualización es 2022-05-30.
Datos generales#
Carga de datos#
Es un archivo que contiene una fila por día y varias columnas con cantidades de casos (positivos, fallecidos, en salón, en UCI, etc.)
# Carga de datos generales
covid_general = pd.read_csv("datos/ministerio-salud/covid/05_30_22_CSV_GENERAL.csv", sep=";")
Estructura del conjunto de datos.
# Estructura del conjunto de datos
covid_general.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 816 entries, 0 to 815
Columns: 144 entries, FECHA to ARS_SIQ_UCI
dtypes: float64(118), int64(11), object(15)
memory usage: 918.1+ KB
Visualización de los datos.
# Datos generales
covid_general
| FECHA | SE | positivos | nue_posi | conf_lab | conf_nexo | muj_posi | hom_posi | extranj_posi | costar_posi | ... | CEACOINS_UCI | CEACOINS_SALON | PAUT_UCI | PAUT_SALON | HVITO_UCI | HVITO_SALON | UNICAR_SAL | UNICAR_UCI | ARS-SIQ_SAL | ARS_SIQ_UCI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 06/03/2020 | 10 | 2 | 2 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 07/03/2020 | 10 | 7 | 5 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 08/03/2020 | 11 | 10 | 3 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 09/03/2020 | 11 | 12 | 2 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 10/03/2020 | 11 | 13 | 1 | NaN | NaN | 7.0 | 6.0 | 3.0 | 10.0 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 811 | 26/05/2022 | 21 | 896712 | 3499 | 3272.0 | 227.0 | 460886.0 | 435826.0 | 102478.0 | 794234.0 | ... | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 4.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 812 | 27/05/2022 | 21 | 899404 | 2692 | 2491.0 | 201.0 | 462372.0 | 437032.0 | 102727.0 | 796677.0 | ... | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 813 | 28/05/2022 | 21 | 901542 | 2138 | 1907.0 | 231.0 | 463595.0 | 437947.0 | 103010.0 | 798532.0 | ... | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 814 | 29/05/2022 | 22 | 903213 | 1671 | 1603.0 | 68.0 | 464547.0 | 438666.0 | 103241.0 | 799972.0 | ... | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 815 | 30/05/2022 | 22 | 904934 | 1721 | 1648.0 | 73.0 | 465503.0 | 439431.0 | 103460.0 | 801474.0 | ... | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0.0 |
816 rows × 144 columns
Puede notarse una cantidad muy grande de columnas (no todas son necesarias) y que la columna correspondiente a la fecha es una hilera de caracteres y no de tipo Date. También que hay algunos nombres de columnas en mayúsculas y otros en minúsculas.
Reducción, cambio de nombre y cambio de tipo de datos de columnas#
# Reducción de columnas
covid_general = covid_general[["FECHA", "positivos", "activos", "RECUPERADOS", "fallecidos",
"nue_posi", "nue_falleci", "salon", "UCI"]]
# Cambio de nombre de las columnas a minúsculas y a nombres más claros
covid_general = covid_general.rename(columns={"FECHA": "fecha",
"RECUPERADOS": "recuperados",
"nue_posi": "nuevos_positivos",
"nue_falleci": "nuevos_fallecidos",
"UCI": "uci"})
# Cambio del tipo de datos del campo de fecha
covid_general["fecha"] = pd.to_datetime(covid_general["fecha"], format="%d/%m/%Y")
# Despliegue de los cambios
covid_general
| fecha | positivos | activos | recuperados | fallecidos | nuevos_positivos | nuevos_fallecidos | salon | uci | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-03-06 | 2 | 2 | 0 | 0 | 2 | 0 | NaN | NaN |
| 1 | 2020-03-07 | 7 | 7 | 0 | 0 | 5 | 0 | NaN | NaN |
| 2 | 2020-03-08 | 10 | 10 | 0 | 0 | 3 | 0 | NaN | NaN |
| 3 | 2020-03-09 | 12 | 12 | 0 | 0 | 2 | 0 | NaN | NaN |
| 4 | 2020-03-10 | 13 | 13 | 0 | 0 | 1 | 0 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 811 | 2022-05-26 | 896712 | 31441 | 856766 | 8505 | 3499 | 6 | 322.0 | 47.0 |
| 812 | 2022-05-27 | 899404 | 33124 | 857772 | 8508 | 2692 | 3 | 328.0 | 47.0 |
| 813 | 2022-05-28 | 901542 | 34163 | 858862 | 8517 | 2138 | 9 | 338.0 | 44.0 |
| 814 | 2022-05-29 | 903213 | 34507 | 860184 | 8522 | 1671 | 5 | 334.0 | 51.0 |
| 815 | 2022-05-30 | 904934 | 35698 | 860711 | 8525 | 1721 | 3 | 333.0 | 52.0 |
816 rows × 9 columns
Datos cantonales#
Son cuatro archivos con casos positivos, activos, recuperados y fallecidos. Cada archivo tiene una fila para cada uno de los 82 cantones y una fila adicional para “Otros”. Hay una columna por cada día muestreado, con la cantidad de casos del tipo respectivo.
Carga de datos#
# Carga de casos positivos
covid_cantonal_positivos = pd.read_csv("datos/ministerio-salud/covid/05_30_22_CSV_POSITIVOS.csv",
sep=";",
encoding="iso-8859-1") # para leer tildes y otros caracteres
# Carga de casos activos
covid_cantonal_activos = pd.read_csv("datos/ministerio-salud/covid/05_30_22_CSV_ACTIVOS.csv",
sep=";",
encoding="iso-8859-1") # para leer tildes y otros caracteres
# Carga de casos recuperados
covid_cantonal_recuperados = pd.read_csv("datos/ministerio-salud/covid/05_30_22_CSV_RECUP.csv",
sep=";",
encoding="iso-8859-1") # para leer tildes y otros caracteres
# Carga de casos fallecidos
covid_cantonal_fallecidos = pd.read_csv("datos/ministerio-salud/covid/05_30_22_CSV_FALLECIDOS.csv",
sep=";",
encoding="iso-8859-1") # para leer tildes y otros caracteres
Estructura de los conjuntos de datos.
# Estructura de los conjuntos de datos.
covid_cantonal_positivos.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 84 entries, 0 to 83
Columns: 811 entries, cod_provin to 30/05/2022
dtypes: float64(809), object(2)
memory usage: 532.3+ KB
Visualización inicial de los datos.
# Casos positivos
covid_cantonal_positivos
| cod_provin | provincia | cod_canton | canton | 15/03/2020 | 16/03/2020 | 17/03/2020 | 18/03/2020 | 19/03/2020 | 20/03/2020 | ... | 21/05/2022 | 22/05/2022 | 23/05/2022 | 24/05/2022 | 25/05/2022 | 26/05/2022 | 27/05/2022 | 28/05/2022 | 29/05/2022 | 30/05/2022 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | San José | 112.0 | Acosta | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 3967.0 | 3974.0 | 3978.0 | 4008.0 | 4012.0 | 4026.0 | 4049.0 | 4054.0 | 4081.0 | 4104.0 |
| 1 | 1.0 | San José | 110.0 | Alajuelita | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 18696.0 | 18711.0 | 18725.0 | 18763.0 | 18802.0 | 18842.0 | 18887.0 | 18918.0 | 18952.0 | 18973.0 |
| 2 | 1.0 | San José | 106.0 | Aserrí | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 10680.0 | 10704.0 | 10716.0 | 10729.0 | 10753.0 | 10782.0 | 10812.0 | 10829.0 | 10852.0 | 10880.0 |
| 3 | 1.0 | San José | 118.0 | Curridabat | 0.0 | 0.0 | 1.0 | 2.0 | 3.0 | 5.0 | ... | 14183.0 | 14200.0 | 14216.0 | 14268.0 | 14329.0 | 14382.0 | 14433.0 | 14459.0 | 14486.0 | 14518.0 |
| 4 | 1.0 | San José | 103.0 | Desamparados | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 5.0 | ... | 42546.0 | 42611.0 | 42654.0 | 42762.0 | 42843.0 | 42985.0 | 43084.0 | 43147.0 | 43208.0 | 43283.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 79 | 7.0 | Limón | 702.0 | Pococí | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 20167.0 | 20196.0 | 20210.0 | 20243.0 | 20268.0 | 20355.0 | 20379.0 | 20410.0 | 20428.0 | 20449.0 |
| 80 | 7.0 | Limón | 703.0 | Siquirres | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 10226.0 | 10235.0 | 10248.0 | 10265.0 | 10271.0 | 10301.0 | 10315.0 | 10328.0 | 10339.0 | 10349.0 |
| 81 | 7.0 | Limón | 704.0 | Talamanca | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 5415.0 | 5415.0 | 5419.0 | 5425.0 | 5429.0 | 5437.0 | 5444.0 | 5457.0 | 5464.0 | 5468.0 |
| 82 | 9.0 | Otros | 999.0 | Otros | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 7.0 | ... | 350.0 | 350.0 | 350.0 | 350.0 | 350.0 | 351.0 | 351.0 | 351.0 | 351.0 | 352.0 |
| 83 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
84 rows × 811 columns
Puede notarse una cantidad muy grande de columnas y también la presencia de caracteres especiales (/) en muchos de los nombres de estas. También que hay una fila con un cantón correspondiente a “Otros” y otra con valores nulos.
Reducción y cambio de nombre de columnas y eliminación de filas innecesarias#
Se reduce la cantidad de columnas, de manera que solo se conservan las que corresponde a la última fecha muestreada, al nombre del cantón y al de la provincia. También se eliminan las filas con valores nulos u “Otros”.
# Reducción de columnas
covid_cantonal_positivos = covid_cantonal_positivos[["provincia", "canton", "30/05/2022"]]
covid_cantonal_fallecidos = covid_cantonal_fallecidos[["provincia", "canton", "30/05/2022"]]
covid_cantonal_recuperados = covid_cantonal_recuperados[["provincia", "canton", "30/05/2022"]]
covid_cantonal_activos = covid_cantonal_activos[["provincia", "canton", "30/05/2022"]]
# Eliminación de fila con valores nulos
covid_cantonal_positivos = covid_cantonal_positivos.dropna(how='all')
covid_cantonal_fallecidos = covid_cantonal_fallecidos.dropna(how='all')
covid_cantonal_recuperados = covid_cantonal_recuperados.dropna(how='all')
covid_cantonal_activos = covid_cantonal_activos.dropna(how='all')
# Eliminación de fila con canton=="Otros"
covid_cantonal_positivos = covid_cantonal_positivos[covid_cantonal_positivos["canton"] != "Otros"]
covid_cantonal_fallecidos = covid_cantonal_fallecidos[covid_cantonal_fallecidos["canton"] != "Otros"]
covid_cantonal_recuperados = covid_cantonal_recuperados[covid_cantonal_recuperados["canton"] != "Otros"]
covid_cantonal_activos = covid_cantonal_activos[covid_cantonal_activos["canton"] != "Otros"]
# Cambio de nombre de columnas
covid_cantonal_positivos = covid_cantonal_positivos.rename(columns={"30/05/2022": "positivos"})
covid_cantonal_fallecidos = covid_cantonal_fallecidos.rename(columns={"30/05/2022": "fallecidos"})
covid_cantonal_recuperados = covid_cantonal_recuperados.rename(columns={"30/05/2022": "recuperados"})
covid_cantonal_activos = covid_cantonal_activos.rename(columns={"30/05/2022": "activos"})
# Despliegue de los cambios
covid_cantonal_positivos
| provincia | canton | positivos | |
|---|---|---|---|
| 0 | San José | Acosta | 4104.0 |
| 1 | San José | Alajuelita | 18973.0 |
| 2 | San José | Aserrí | 10880.0 |
| 3 | San José | Curridabat | 14518.0 |
| 4 | San José | Desamparados | 43283.0 |
| ... | ... | ... | ... |
| 77 | Limón | Limón | 16822.0 |
| 78 | Limón | Matina | 5822.0 |
| 79 | Limón | Pococí | 20449.0 |
| 80 | Limón | Siquirres | 10349.0 |
| 81 | Limón | Talamanca | 5468.0 |
82 rows × 3 columns
Pasajeros del Titanic#
Este es el conjunto de datos de entrenamiento de la competencia Titanic - Machine Learning from Disaster organizada por Kaggle. El archivo también está disponible en https://github.com/pf3311-cienciadatosgeoespaciales/2021-iii/blob/main/contenido/b/datos/entrenamiento.csv.
Carga de datos#
# Pasajeros en el conjunto de datos de entrenamiento
titanic = pd.read_csv("datos/kaggle/titanic/pasajeros-titanic-entrenamiento.csv")
# Despliegue de los datos
titanic
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 887 | 0 | 2 | Montvila, Rev. Juozas | male | 27.0 | 0 | 0 | 211536 | 13.0000 | NaN | S |
| 887 | 888 | 1 | 1 | Graham, Miss. Margaret Edith | female | 19.0 | 0 | 0 | 112053 | 30.0000 | B42 | S |
| 888 | 889 | 0 | 3 | Johnston, Miss. Catherine Helen "Carrie" | female | NaN | 1 | 2 | W./C. 6607 | 23.4500 | NaN | S |
| 889 | 890 | 1 | 1 | Behr, Mr. Karl Howell | male | 26.0 | 0 | 0 | 111369 | 30.0000 | C148 | C |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
891 rows × 12 columns
Visualizaciones de datos#
Las siguientes visualizaciones se implementan con los métodos de matplotlib integrados en pandas. pandas puede utilizar varias bibliotecas de graficación y matplotlib es la que emplea por defecto. Los gráficos resultantes se complementan con el módulo pyplot, para aspectos como títulos, tamaños y otros.
Se desarrollan también algunos ejemplos con seaborn.
Histogramas#
Un histograma es una representación gráfica de la distribución de una variable numérica en forma de barras (llamadas en inglés bins). La longitud de cada barra representa la frecuencia de un rango de valores de la variable. La graficación de la distribución de las variables es, frecuentemente, una de las primeras tareas que se realiza cuando se explora un conjunto de datos.
En pandas, los histogramas se crean con el método pandas.DataFrame.hist(). Elementos adicionales del gráfico, como el título y las etiquetas de los ejes, pueden agregarse con matplotlib.pyplot.
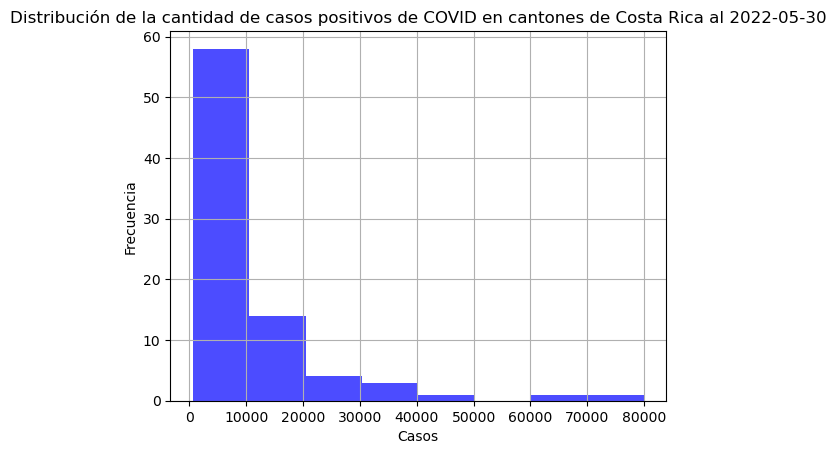
El siguiente histograma muestra la distribución de la variable correspondiente a los casos de COVID positivos en los cantones de Costa Rica.
# Histograma de casos positivos en cantones
covid_cantonal_positivos["positivos"].hist(
bins=8,
color="blue",
alpha=0.7)
# Título y etiquetas en los ejes
plt.title("Distribución de la cantidad de casos positivos de COVID en cantones de Costa Rica al 2022-05-30")
plt.xlabel("Casos")
plt.ylabel("Frecuencia")
Text(0, 0.5, 'Frecuencia')
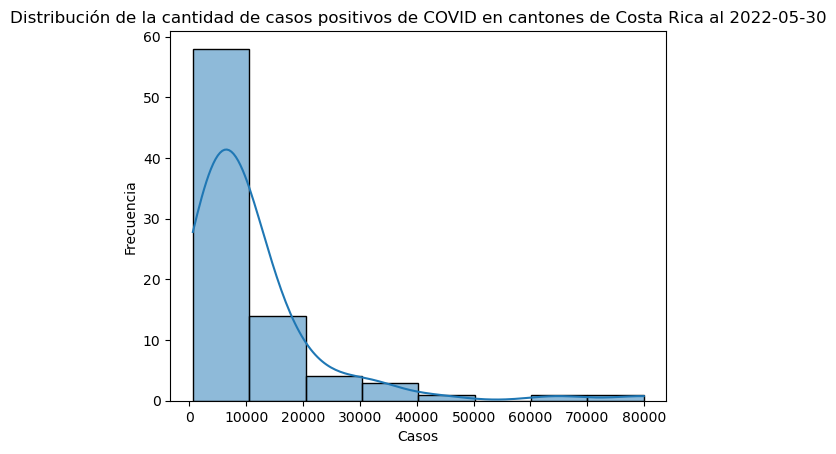
El método seaborn.histplot() permite crear histogramas con seaborn. El argumento kde se utiliza para añadir una estimación de densidad del kernel (Kernel Density Estimation, KDE), una curva que muestra la densidad de los datos.
# Histograma y curva de densidad
sns.histplot(data=covid_cantonal_positivos, x="positivos", bins=8, kde=True)
# Título y etiquetas en los ejes
plt.title("Distribución de la cantidad de casos positivos de COVID en cantones de Costa Rica al 2022-05-30")
plt.xlabel("Casos")
plt.ylabel("Frecuencia")
Text(0, 0.5, 'Frecuencia')
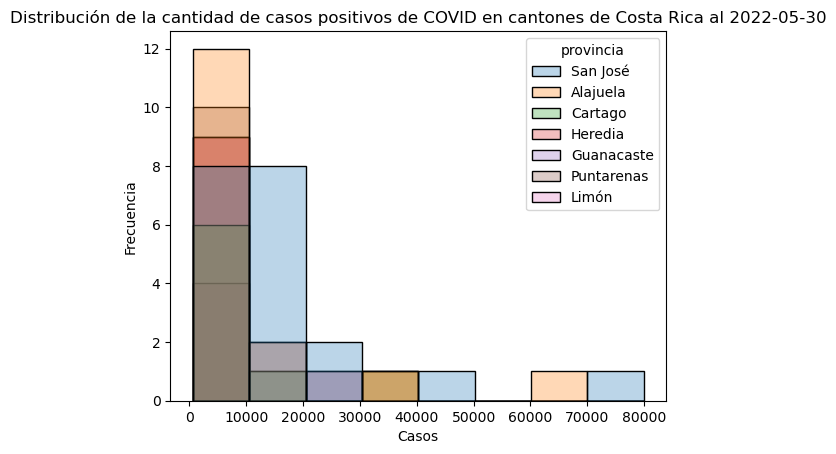
El argumento hue se usa para mostrar una división de cada bin de acuerdo con el valor de alguna columna.
# Histograma con "bins" divididos por provincia
sns.histplot(data=covid_cantonal_positivos,
x="positivos",
bins=8,
hue="provincia",
alpha=0.3)
# Título y etiquetas en los ejes
plt.title("Distribución de la cantidad de casos positivos de COVID en cantones de Costa Rica al 2022-05-30")
plt.xlabel("Casos")
plt.ylabel("Frecuencia")
Text(0, 0.5, 'Frecuencia')
Ejercicios#
Construya un histograma que muestre la distribución de la edad de los pasajeros del Titanic. Incluya una curva de densidad.
Agregue la distribución de la variable de sobrevivencia al histograma del ejercicio anterior.
Construya un histograma que muestre la distribución de la cantidad de padres e hijos que viajaban con los pasajeros del Titanic. Incluya una curva de densidad.
Agregue la distribución de la variable de sobrevivencia al histograma del ejercicio anterior.
Construya un histograma que muestre la distribución de la cantidad de hermanos y cónyugues que viajaban con los pasajeros del Titanic. Incluya una curva de densidad.
Agregue la distribución de la variable de sobrevivencia al histograma del ejercicio anterior.
Gráficos de caja#
Un gráfico de caja (boxplot) muestra información de una variable numérica a través de su mediana, sus cuartiles (Q1, Q2 y Q3) y sus valores atípicos.
En pandas, los gráficos de caja se crean con el método pandas.DataFrame.boxplot().
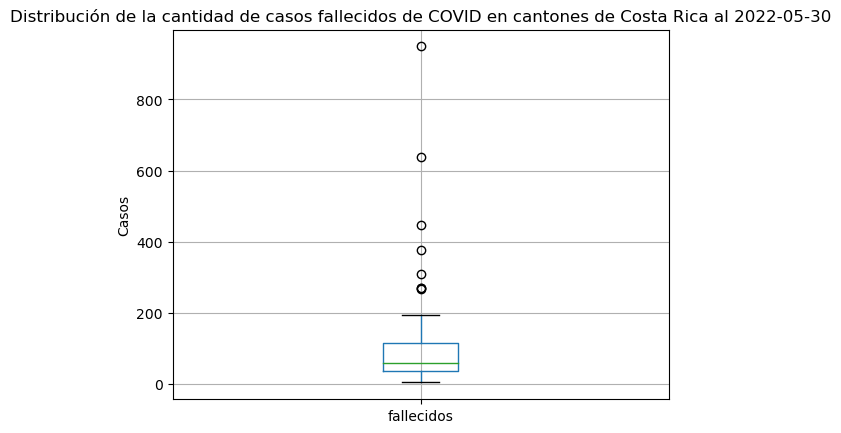
El siguiente diagrama de caja muestra la distribución de la variable correspondiente a los casos de COVID fallecidos en los cantones de Costa Rica.
# Gráfico de caja de casos fallecidos en cantones
covid_cantonal_fallecidos.boxplot(column="fallecidos")
# Título y etiquetas en los ejes
plt.title("Distribución de la cantidad de casos fallecidos de COVID en cantones de Costa Rica al 2022-05-30")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
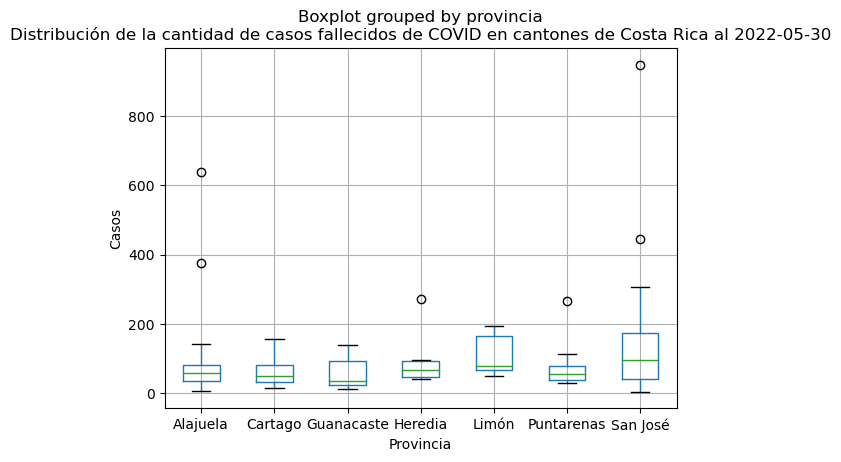
El argumento by puede utilizarse para agrupar los datos por una variable adicional, como la provincia.
# Gráfico de caja de casos fallecidos en cantones, agrupados por provincia
covid_cantonal_fallecidos.boxplot(column="fallecidos", by="provincia")
# Título y etiquetas en los ejes
plt.title("Distribución de la cantidad de casos fallecidos de COVID en cantones de Costa Rica al 2022-05-30")
plt.xlabel("Provincia")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
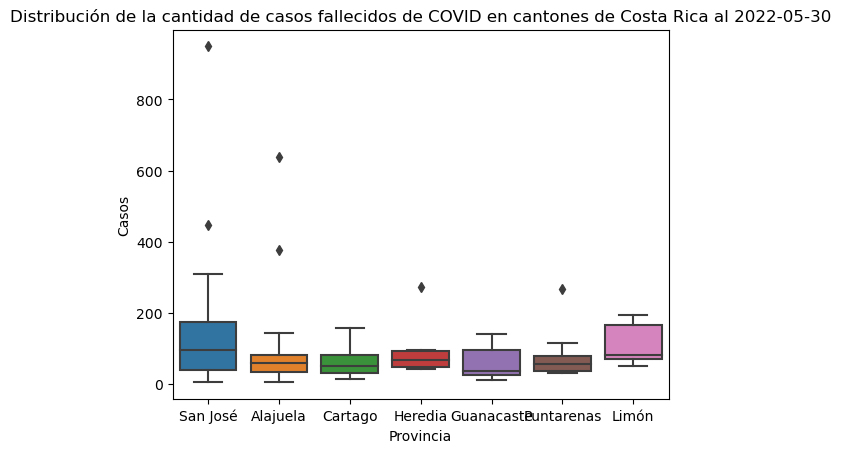
El método seaborn.boxplot() permite crear gráficos de caja con seaborn.
# Gráfico de caja de casos fallecidos en cantones agrupados por provincia
sns.boxplot(y=covid_cantonal_fallecidos["fallecidos"],
x=covid_cantonal_fallecidos["provincia"])
# Título y etiquetas en los ejes
plt.title("Distribución de la cantidad de casos fallecidos de COVID en cantones de Costa Rica al 2022-05-30")
plt.xlabel("Provincia")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
Ejercicios#
Construya un gráfico de caja de la edad de los pasajeros del Titanic.
Agregue la distribución de la variable de sobrevivencia al gráfico del ejercicio anterior.
Construya un gráfico de caja de la cantidad de padres e hijos que viajaban con los pasajeros del Titanic.
Agregue la distribución de la variable de sobrevivencia al gráfico del ejercicio anterior.
Construya un gráfico de caja de la cantidad de hermanos y cónyugues que viajaban con los pasajeros del Titanic.
Agregue la distribución de la variable de sobrevivencia al gráfico del ejercicio anterior.
Gráficos de barras#
Un gráfico de barras se compone de barras rectangulares con longitud proporcional a estadísticas (ej. frecuencias, promedios, mínimos, máximos) asociadas a una variable categórica o discreta. Las barras pueden ser horizontales o verticales y se recomienda que estén ordenadas según su longitud, a menos que exista un orden inherente a la variable (ej. el orden de los días de la semana o de los meses del año).
En pandas, los gráficos de barras se crean con los métodos pandas.DataFrame.plot.bar(), para barras verticales, y pandas.DataFrame.plot.barh(), para barras horizontales.
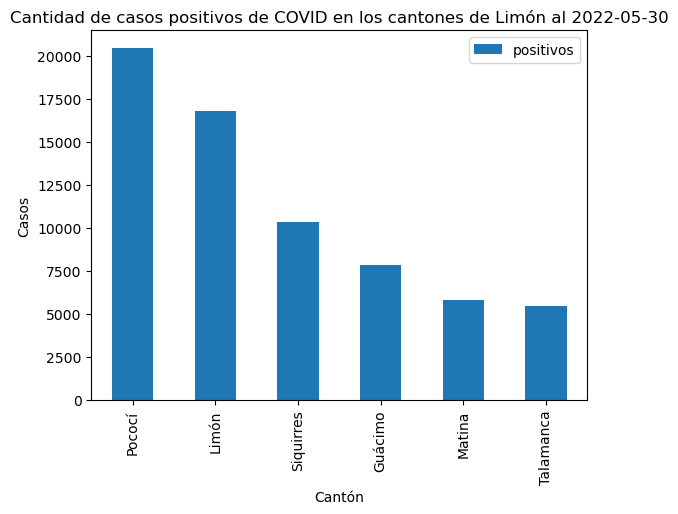
El siguiente gráfico de barras verticales muestra las cantidades de casos positivos en los cantones de Limón.
# Subconjunto de cantones de la provincia de Limón
covid_limon_positivos = covid_cantonal_positivos[covid_cantonal_positivos["provincia"] == "Limón"]
# Se establece la columna "canton" como índice del dataframe
# y este se ordena por la cantidad de casos positivos antes de
# hacer el gráfico con plot.bar()
covid_limon_positivos.set_index("canton") \
.sort_values(by="positivos", ascending=False) \
.plot.bar()
plt.title("Cantidad de casos positivos de COVID en los cantones de Limón al 2022-05-30")
plt.xlabel("Cantón")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
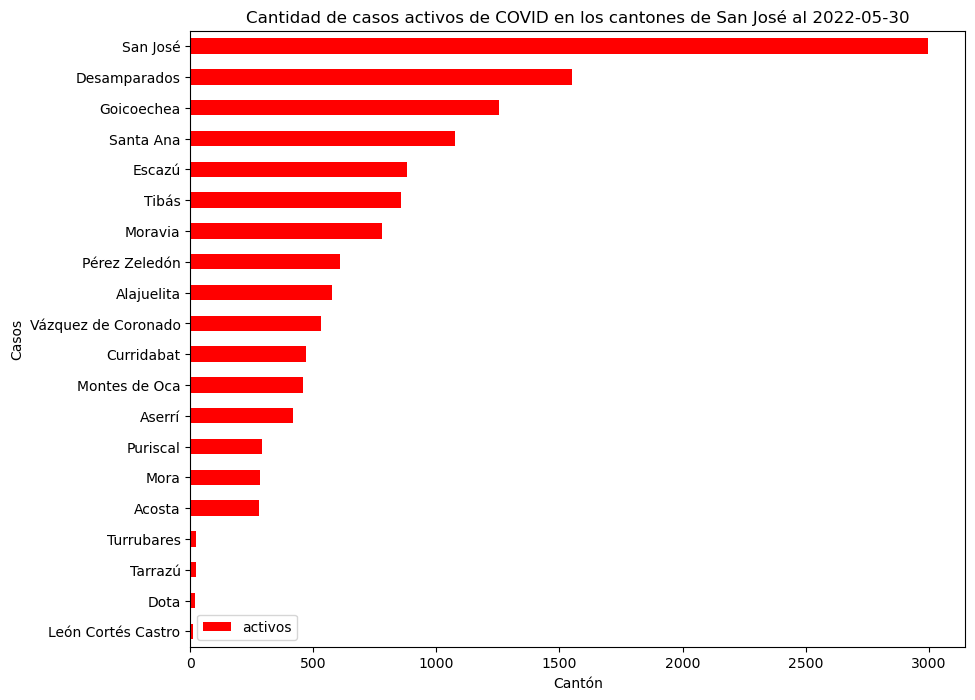
El siguiente gráfico de barras horizontales muestra las cantidades de casos activos en los cantones de San José.
# Subconjunto de cantones de la provincia de San José
covid_sanjose_activos = covid_cantonal_activos[covid_cantonal_activos["provincia"] == "San José"]
# Se establece la columna "canton" como índice del dataframe
# y este se ordena por la cantidad de casos antes de
# hacer el gráfico con plot.barh().
# También se establece el tamaño del gráfico con figsize()
covid_sanjose_activos.set_index("canton").sort_values(by="activos").plot.barh(color="red", figsize=(10, 8))
plt.title("Cantidad de casos activos de COVID en los cantones de San José al 2022-05-30")
plt.xlabel("Cantón")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
En el siguiente ejemplo, se utiliza el método pandas.DataFrame.groupby() para agrupar los datos por provincia y sumar los casos positivos.
# Suma de casos positivos por provincia
covid_provincial_positivos = covid_cantonal_positivos.groupby(["provincia"], as_index=False)["positivos"] \
.sum()
covid_provincial_positivos
# Se establece la columna "provincia" como índice del dataframe
# y este se ordena por la cantidad de casos positivos antes de
# hacer el gráfico con plot.bar()
covid_provincial_positivos.set_index("provincia") \
.sort_values(by="positivos", ascending=False) \
.plot.bar()
plt.title("Cantidad de casos positivos de COVID en las provincias de Costa Rica al 2022-05-30")
plt.xlabel("Provincia")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
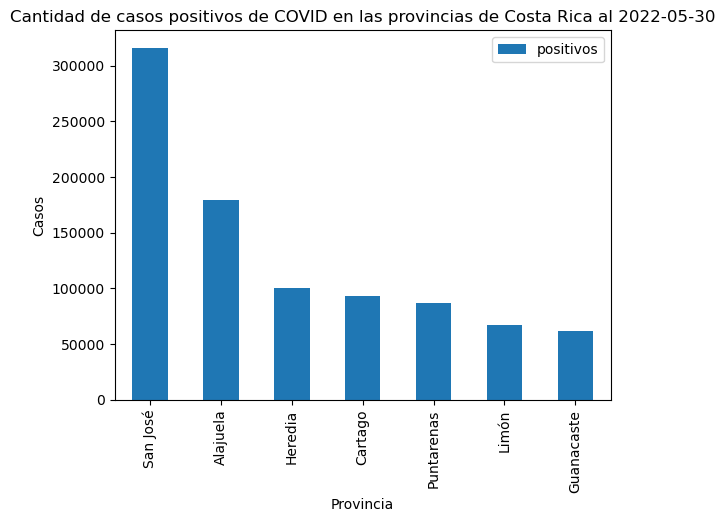
El método seaborn.barplot() permite crear gráficos de barras con seaborn.
El siguiente gráfico muestra la proporción de sobrevivientes por sexo y clase entre los pasajeros del Titanic.
# Gráfico de barras
sns.barplot(data=titanic, x="Sex", y="Survived", hue="Pclass")
plt.title("Proporción de sobrevivientes del Titanic por sexo y clase")
plt.xlabel("Sexo")
plt.ylabel("Proporción de sobrevivientes")
Text(0, 0.5, 'Proporción de sobrevivientes')
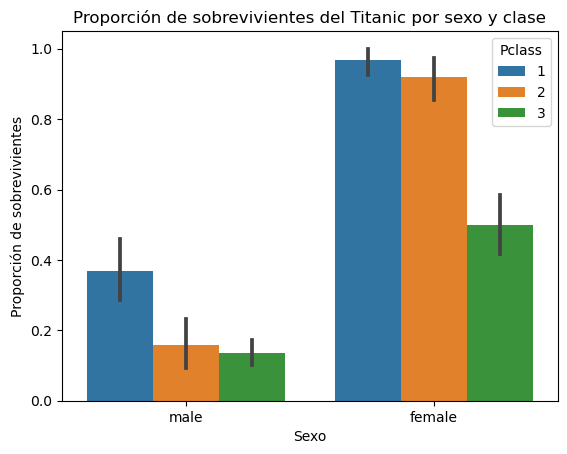
Ejercicios#
Convierta el gráfico de barras del ejemplo de proporción de sobrevivientes por sexo y clase entre los pasajeros del Titanic, en un gráfico de barras apiladas.
Gráficos de pastel#
Un gráfico de pastel representa porcentajes y porciones en secciones (slices) de un círculo. Son muy populares, pero también criticados debido a la dificultad del cerebro humano de comparar áreas de sectores circulares, por lo que algunos expertos recomiendan sustituirlos por otros tipos de gráficos como, por ejemplo, gráficos de barras.
En pandas, los gráficos de barras se crean con el método pandas.DataFrame.plot.pie().
El siguiente gráfico de barras verticales muestra las cantidades de casos positivos en los cantones de Limón.
# Subconjunto de cantones de la provincia de Limón
covid_limon_positivos = covid_cantonal_positivos[covid_cantonal_positivos["provincia"] == "Limón"]
# Se establece la columna "canton" como índice del dataframe
# y este se ordena por la cantidad de casos positivos antes de
# hacer el gráfico con plot.bar()
covid_limon_positivos.set_index("canton") \
.sort_values(by="positivos", ascending=False) \
.plot.pie(y="positivos", autopct="%1.0f%%")
plt.title("Porcentaje de casos positivos de COVID en los cantones de Limón al 2022-05-30")
plt.ylabel("")
plt.legend(bbox_to_anchor=(1.0, 1.0))
<matplotlib.legend.Legend at 0x7f32c1df12d0>
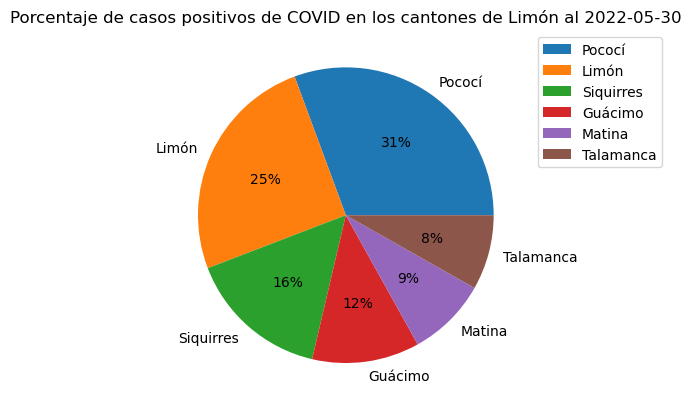
Seaborn no cuenta con un método para dibujar gráficos de pastel. Sin embargo, para aprovechas las capacidades de esta biblioteca, puede crearse el gráfico con matplotlib y utilizar uno de los esquemas de colores de seaborn con el método seaborn.color_palette(). Para más información sobre el manejo de colores en seaborn, puede consultar Choosing color palettes.
# Suma de casos positivos por provincia
covid_provincial_positivos = covid_cantonal_positivos.groupby(["provincia"], as_index=False)["positivos"].sum()
covid_provincial_positivos
# Paleta de colores de seaborn
colores = sns.color_palette('deep')[0:7]
# colores = sns.color_palette('muted')[0:7]
# colores = sns.color_palette('bright')[0:7]
# colores = sns.color_palette('pastel')[0:7]
# colores = sns.color_palette('dark')[0:7]
# colores = sns.color_palette('colorblind')[0:7]
# Se establece la columna "provincia" como índice del dataframe
# y este se ordena por la cantidad de casos positivos antes de
# hacer el gráfico con plot.bar()
covid_provincial_positivos.set_index("provincia") \
.sort_values(by="positivos", ascending=False) \
.plot \
.pie(y="positivos", autopct="%1.0f%%", colors = colores)
plt.title("Procentaje de casos positivos de COVID en provincias al 2022-05-30")
plt.ylabel("")
plt.legend(bbox_to_anchor=(1.0, 1.0))
<matplotlib.legend.Legend at 0x7f32c1b9d780>
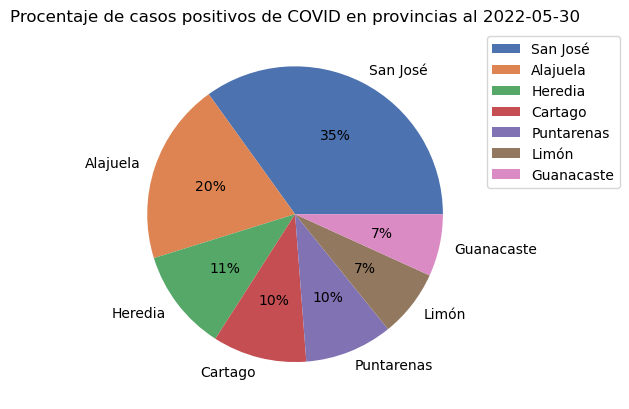
Ejercicios#
Construya un gráfico de pastel que muestre la proporción de pasajeros sobrevivientes y fallecidos que viajaban en el Titanic.
Construya un gráfico de pastel que muestre la proporción de cada sexo (masculino, femenino) de pasajeros que viajaban en el Titanic.
Construya un gráfico de pastel que muestre la proporción de cada clase de pasajeros (1, 2, 3) que viajaban en el Titanic.
Gráficos de dispersión#
Un gráfico de dispersión (scatterplot) despliega los valores de dos variables numéricas, como puntos en un sistema de coordenadas. El valor de una variable se despliega en el eje X y el de la otra variable en el eje Y. Variables adicionales pueden ser mostradas mediante atributos de los puntos, tales como su tamaño, color o forma.
En pandas, los gráficos de barras se crean con el método pandas.DataFrame.plot.scatter().
Seguidamente, se utiliza un gráfico de dispersión para mostrar las cantidades diarias de pacientes hospitalizados en salón y de pacientes hospitalizados en unidades de cuidados intensivos (UCI) por causa del COVID, del conjunto de datos generales de COVID.
# Se agrega una columna correspondiente al año,
# para luego utilizarla para colorear los puntos
covid_general["anio"] = pd.DatetimeIndex(covid_general['fecha']).year
# Gráfico de dispersión
covid_general.plot.scatter(x="salon", y="uci", c="anio", colormap="viridis")
plt.title("Pacientes de COVID hospitalizados en salón vs pacientes hospitalizados en UCI al 2020-05-30")
plt.xlabel("Pacientes hospitalizados en salón")
plt.ylabel("Pacientes hospitalizados en UCI")
Text(0, 0.5, 'Pacientes hospitalizados en UCI')
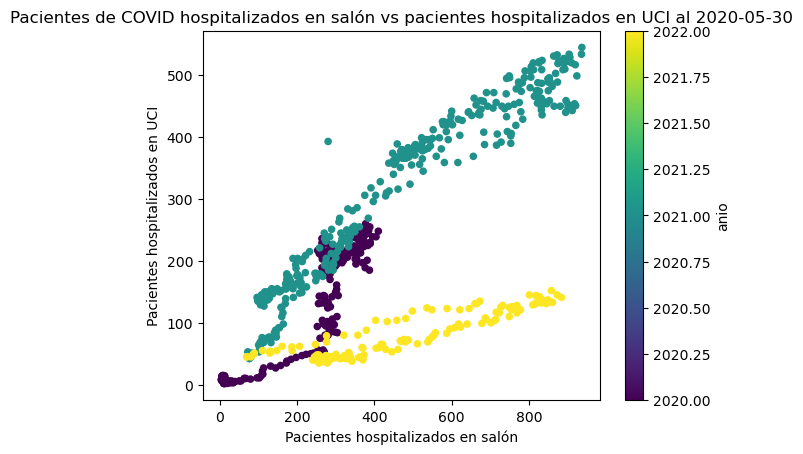
El método seaborn.scatterplot() permite crear gráficos de dispersión con seaborn.
El mismo gráfico del ejemplo anterior se presenta seguidamente, generado con seaborn.
# Gráfico de dispersión
sns.scatterplot(data=covid_general, x="salon", y="uci", hue="anio", palette="deep")
plt.title("Pacientes de COVID hospitalizados en salón vs pacientes hospitalizados en UCI al 2020-05-30")
plt.xlabel("Pacientes hospitalizados en salón")
plt.ylabel("Pacientes hospitalizados en UCI")
Text(0, 0.5, 'Pacientes hospitalizados en UCI')
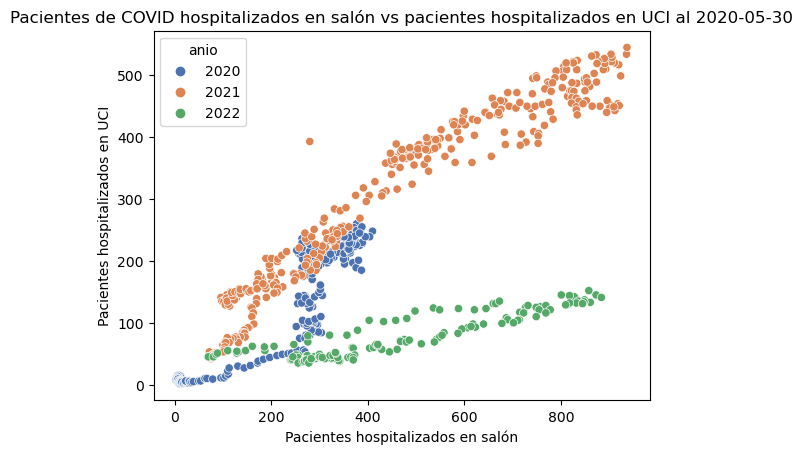
El método seaborn.lmplot grafica un modelo de regresión, que permite apreciar más fácilmente tendencias en los datos.
# Gráfico de dispersión y modelo de regresión
sns.lmplot(data=covid_general,
x="salon",
y="uci",
lowess=True,
hue="anio",
palette="deep",
line_kws={"color": "black"})
plt.title("Pacientes de COVID hospitalizados en salón vs pacientes hospitalizados en UCI al 2020-05-30")
plt.xlabel("Pacientes hospitalizados en salón")
plt.ylabel("Pacientes hospitalizados en UCI")
Text(41.124374999999986, 0.5, 'Pacientes hospitalizados en UCI')
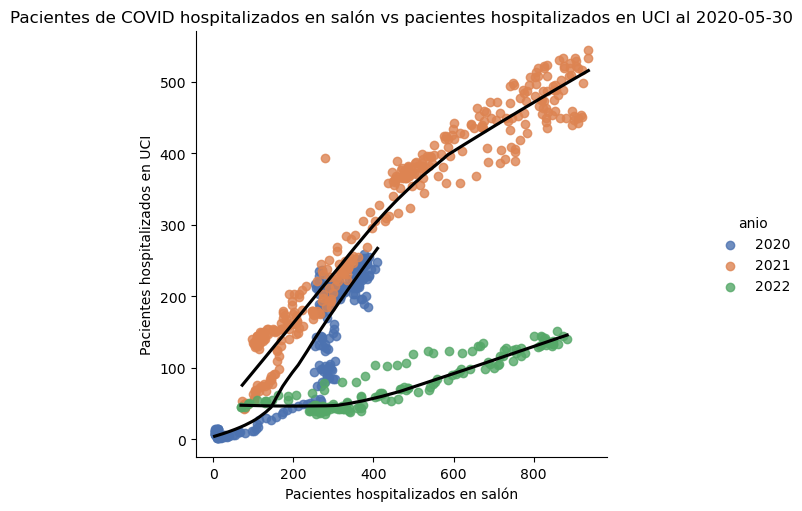
Ejercicios#
En un gráfico de dispersión, muestre las variables de casos positivos y casos fallecidos de COVID, del conjunto de datos generales.
Gráficos de líneas#
Un gráfico de líneas muestra información en la forma de puntos de datos, llamados marcadores (markers), conectados por segmentos de líneas rectas. Es similar a un gráfico de dispersión pero, además de los segmentos de línea, tiene la particularidad de que los datos están ordenados, usualmente con respecto al eje X. Los gráficos de línea son usados frecuentemente para mostrar tendencias a través del tiempo.
En pandas, los gráficos de líneas se crean con el método pandas.DataFrame.plot.line().
El siguiente gráfico de líneas muestra la cantidad de casos positivos de COVID acumulados a través del tiempo, de acuerdo con el conjunto de datos generales.
# Gráfico de líneas
covid_general.plot.line(x="fecha", y=["positivos"])
plt.title("Casos positivos acumulados de COVID en Costa Rica al 2020-05-30")
plt.xlabel("Fecha")
plt.ylabel("Casos positivos")
Text(0, 0.5, 'Casos positivos')
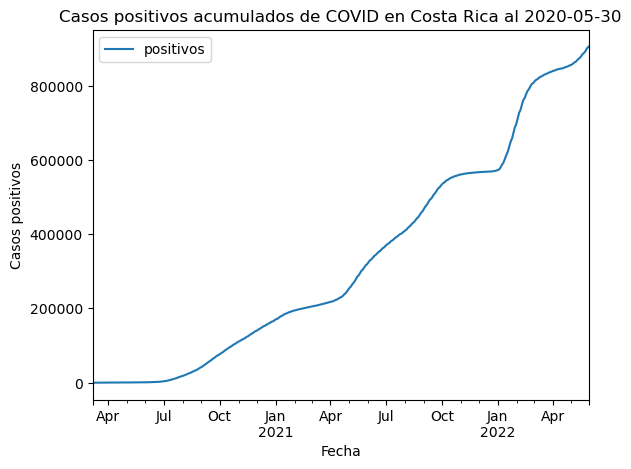
El siguiente gráfico le agrega al anterior las variables de casos activos, recuperados y fallecidos. También especifica un color para cada variable.
# Gráfico de líneas
covid_general.plot.line(x="fecha",
y=["positivos", "activos", "recuperados", "fallecidos"],
color={"positivos": "blue",
"activos": "red",
"recuperados": "green",
"fallecidos": "black"}
)
plt.title("Casos positivos acumulados de COVID en Costa Rica al 2020-05-30")
plt.xlabel("Fecha")
plt.ylabel("Casos")
Text(0, 0.5, 'Casos')
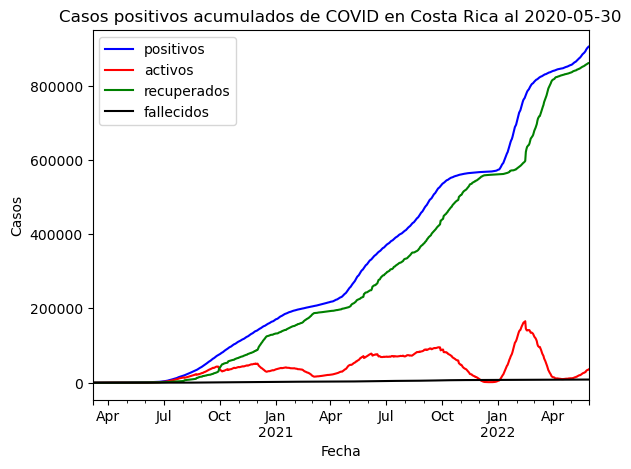
# Gráfico de líneas
sns.lineplot(data=covid_general, x="fecha", y="positivos", color="blue")
sns.lineplot(data=covid_general, x="fecha", y="activos", color="red")
sns.lineplot(data=covid_general, x="fecha", y="recuperados", color="green")
sns.lineplot(data=covid_general, x="fecha", y="fallecidos", color="black")
plt.title("Casos positivos acumulados de COVID en Costa Rica al 2020-05-30")
plt.xlabel("Fecha")
plt.ylabel("Casos")
plt.rcParams["figure.figsize"] = [10, 10]
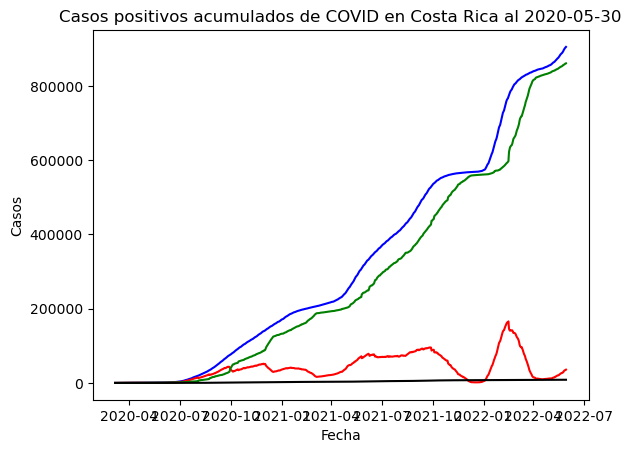
El método seaborn.lineplot() permite crear gráficos de líneas con seaborn.
El mismo gráfico del ejemplo anterior se presenta seguidamente, generado con seaborn.
Ejercicios#
En un gráfico de líneas, muestre las variables de casos positivos de hombres y de casos positivos de mujeres, del conjunto de datos generales de COVID.